از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
TensorFlowیک چارچوب یادگیری عمیق به خوبی تثبیت شده است، و کراس API رسمی سطح بالای آن است که ایجاد مدل ها را ساده می کند. تشخیص/طبقه بندی تصویر یک کار رایج است و خوشبختانه با Keras نسبتاً ساده و ساده است.
در این راهنما، ما نگاهی به روش طبقه بندی/تشخیص تصاویر در پایتون با Keras خواهیم داشت.
اگر می خواهید با کد بازی کنید یا به سادگی آن را کمی عمیق تر مطالعه کنید، پروژه در آپلود می شود GitHub.
در این راهنما، ما یک CNN سفارشی می سازیم و آن را از ابتدا آموزش می دهیم. برای راهنمای پیشرفته تر، می توانید از اهرم استفاده کنید آموزش انتقالی برای انتقال بازنمایی دانش با معماریهای با کارایی بالا – طبقهبندی تصویر ما با آموزش انتقال را در Keras بخوانید – مدلهای پیشرفته CNN را ایجاد کنید!
تعاریف
اگر واضح نیستید روی مفاهیم اساسی در پس طبقه بندی تصاویر، درک کامل بقیه این راهنما دشوار خواهد بود. بنابراین قبل از اینکه ادامه دهیم، اجازه دهید لحظه ای را به تعریف برخی از اصطلاحات اختصاص دهیم.
TensorFlow/Keras
TensorFlow یک کتابخانه متن باز است که توسط تیم Google Brain برای پایتون ایجاد شده است. TensorFlow بسیاری از الگوریتمها و مدلهای مختلف را با هم جمعآوری میکند و کاربر را قادر میسازد تا شبکههای عصبی عمیق را برای استفاده در کارهایی مانند تشخیص/طبقهبندی تصویر و پردازش زبان طبیعی پیادهسازی کند. TensorFlow یک چارچوب قدرتمند است که با پیاده سازی یک سری از گره های پردازشی، هر کدام عمل می کند node نشان دهنده یک عملیات ریاضی است که کل سری گره ها را “گراف” می نامند.
به لحاظ کراس، سطح بالایی است API (رابط برنامه نویسی برنامه) که می تواند از توابع TensorFlow در زیر استفاده کند (و همچنین سایر کتابخانه های ML مانند Theano). Keras با کاربر پسند بودن و مدولار بودن به عنوان اصول راهنما طراحی شده است. از نظر عملی، Keras اجرای بسیاری از توابع قدرتمند اما اغلب پیچیده TensorFlow را تا حد امکان ساده میکند و برای کار با پایتون بدون هیچ گونه تغییر یا پیکربندی عمده پیکربندی شده است.
طبقه بندی تصویر (تشخیص)
تشخیص تصویر به وظیفه وارد کردن یک تصویر به یک شبکه عصبی و خروجی آن نوعی برچسب برای آن تصویر اشاره دارد. برچسبی که خروجی شبکه با یک کلاس از پیش تعریف شده مطابقت دارد. ممکن است چندین کلاس وجود داشته باشد که تصویر را می توان به عنوان یا فقط یک طبقه بندی کرد. اگر یک کلاس واحد وجود دارد، اصطلاح “به رسمیت شناختن” اغلب اعمال می شود، در حالی که یک کار تشخیص چند کلاسه اغلب نامیده می شود “طبقه بندی”.
زیرمجموعهای از طبقهبندی تصویر، تشخیص اشیا است، که در آن نمونههای خاصی از اشیاء به عنوان متعلق به یک کلاس خاص مانند حیوانات، ماشینها یا افراد شناسایی میشوند.
برای انجام تشخیص/طبقه بندی تصویر، شبکه عصبی باید انجام دهد استخراج ویژگی. ویژگی ها عناصر داده ای هستند که برای شما مهم است و از طریق شبکه تغذیه می شوند. در مورد خاص تشخیص تصویر، ویژگیها گروههایی از پیکسلها، مانند لبهها و نقاط، یک شی هستند که شبکه برای الگوها تجزیه و تحلیل میکند.
تشخیص ویژگی (یا استخراج ویژگی) است process بیرون کشیدن ویژگی های مربوطه از یک تصویر ورودی به طوری که این ویژگی ها قابل تجزیه و تحلیل باشند. بسیاری از تصاویر حاوی حاشیه نویسی یا ابرداده در مورد تصویر هستند که به شبکه کمک می کند تا ویژگی های مربوطه را پیدا کند.
چگونه شبکه های عصبی تشخیص تصاویر را یاد می گیرند – پرایمر روی شبکه های عصبی کانولوشنال
هنگامی که یک مدل شبکه عصبی را پیاده سازی می کنید، دریافت شهود از روش تشخیص تصاویر توسط یک شبکه عصبی به شما کمک می کند، بنابراین اجازه دهید به طور خلاصه تشخیص تصویر را بررسی کنیم. process در چند بخش بعدی
این بخش برای خدمت به عنوان یک دوره / آغازگر تصادف است روی شبکه های عصبی کانولوشن، و همچنین یک تجدید کننده برای کسانی که با آنها آشنا هستند.

اعتبار: commons.wikimedia.org
اولین لایه یک شبکه عصبی تمام پیکسل های یک تصویر را می گیرد. پس از وارد شدن تمام داده ها به شبکه، فیلترهای مختلفی روی تصویر اعمال می شود که نمایش بخش های مختلف تصویر را تشکیل می دهد. این استخراج ویژگی است و “نقشه های ویژگی” را ایجاد می کند.
این process استخراج ویژگی ها از یک تصویر با یک “لایه کانولوشنال” انجام می شود و کانولوشن به سادگی نمایش بخشی از یک تصویر را تشکیل می دهد. از این مفهوم پیچیدگی است که ما این اصطلاح را دریافت می کنیم شبکه عصبی کانولوشنال (CNN)، نوع شبکه عصبی که بیشتر در طبقه بندی/تشخیص تصاویر استفاده می شود. به تازگی، مبدل ها در طبقه بندی تصاویر نیز شگفتی هایی انجام داده اند که مبتنی بر آن است روی را شبکه عصبی مکرر معماری (RNN).
اگر میخواهید روش عملکرد ایجاد نقشههای ویژگی برای شبکههای Convolutional را تجسم کنید – به نور چراغ قوه روی یک تصویر در یک اتاق تاریک فکر کنید. همانطور که پرتو را روی تصویر میکشید، در مورد ویژگیهای تصویر یاد میگیرید. آ فیلتر کنید چیزی است که شبکه برای شکل دادن به تصویر استفاده می کند و در این استعاره، نور چراغ قوه فیلتر است.
پهنای پرتو چراغ قوه شما میزان تصویری را که در یک زمان بررسی میکنید کنترل میکند و شبکههای عصبی پارامتر مشابهی دارند، اندازه فیلتر. اندازه فیلتر بر تعداد تصویر و تعداد پیکسل در یک زمان بررسی می شود. یک اندازه فیلتر رایج که در CNN ها استفاده می شود 3 است و این اندازه هم ارتفاع و هم عرض را پوشش می دهد، بنابراین فیلتر ناحیه 3×3 پیکسل را بررسی می کند.

اعتبار: commons.wikimedia.org
در حالی که اندازه فیلتر پوشش می دهد ارتفاع و عرض از فیلتر، فیلتر عمق نیز باید مشخص شود.
چگونه یک تصویر دو بعدی عمق دارد؟
تصاویر دیجیتال به صورت ارتفاع، عرض و برخی ارائه می شوند مقدار RGB که رنگ های پیکسل را مشخص می کند، بنابراین “عمق” که ردیابی می شود تعداد کانال های رنگی است که تصویر دارد. تصاویر در مقیاس خاکستری (غیر رنگی) تنها دارای 1 کانال رنگی هستند در حالی که تصاویر رنگی دارای 3 کانال عمقی هستند.
همه اینها به این معنی است که برای یک فیلتر با اندازه 3 اعمال شده بر روی یک تصویر تمام رنگی، ابعاد آن فیلتر 3 x 3 x 3 خواهد بود. برای هر پیکسلی که توسط آن فیلتر پوشانده شده است، شبکه مقادیر فیلتر را با مقادیر موجود ضرب می کند. خود پیکسل ها برای به دست آوردن نمایش عددی آن پیکسل. این process سپس برای کل تصویر انجام می شود تا به یک نمایش کامل برسد. فیلتر بر اساس پارامتری به نام “گام” در بقیه تصویر جابهجا میشود، که مشخص میکند پس از محاسبه مقدار در موقعیت فعلی، فیلتر باید با چند پیکسل جابجا شود. اندازه گام معمولی برای CNN 2 است.
نتیجه نهایی همه این محاسبات یک نقشه ویژگی است. این process معمولاً با بیش از یک فیلتر انجام می شود که به حفظ پیچیدگی تصویر کمک می کند.
توابع فعال سازی
پس از ایجاد نقشه ویژگی تصویر، مقادیری که تصویر را نشان می دهند از طریق یک تابع فعال سازی یا لایه فعال سازی منتقل می شوند. تابع فعال سازی مقادیری را می گیرد که تصویر را نشان می دهد، که به لطف لایه کانولوشن به شکل خطی هستند (یعنی فقط لیستی از اعداد) و غیرخطی بودن آنها را افزایش می دهد زیرا خود تصاویر غیر خطی هستند.
تابع فعال سازی معمولی که برای انجام این کار استفاده می شود a واحد خطی اصلاح شده (ReLU)، اگرچه برخی از توابع فعال سازی دیگر وجود دارد که گهگاه مورد استفاده قرار می گیرند (شما می توانید در مورد آنها مطالعه کنید اینجا).
لایه های ترکیبی
پس از فعال شدن داده ها از طریق a ارسال می شود لایه ادغام. ادغام “پایین نمونه” یک تصویر، به این معنی که اطلاعاتی را که تصویر را نشان می دهد گرفته و فشرده می کند و آن را کوچکتر می کند. استخر process شبکه را انعطافپذیرتر میکند و در تشخیص اشیاء/تصاویر ماهرتر میکند روی ویژگی های مربوطه
وقتی به یک تصویر نگاه میکنیم، معمولاً به تمام اطلاعات موجود در پسزمینه تصویر نمیپردازیم، فقط به ویژگیهایی که به آنها اهمیت میدهیم، مانند افراد یا حیوانات اهمیت میدهیم.
به همین ترتیب، الف لایه ادغام در CNN، بخشهای غیرضروری تصویر را انتزاع میکند، و تنها قسمتهایی از تصویر را که فکر میکند مرتبط هستند، حفظ میکند، همانطور که توسط اندازه مشخص شده لایه ادغام کنترل میشود.
از آنجایی که باید در مورد مرتبط ترین بخش های تصویر تصمیم گیری کند، امید این است که شبکه تنها بخش هایی از تصویر را که واقعاً نمایانگر شی مورد نظر است، بیاموزد. این به پیشگیری کمک می کند بیش از حد، جایی که شبکه جنبه های مورد آموزشی را خیلی خوب یاد می گیرد و نمی تواند به داده های جدید تعمیم دهد.

اعتبار: commons.wikimedia.org
روش های مختلفی برای جمع کردن مقادیر وجود دارد، اما حداکثر ادغام بیشتر مورد استفاده قرار می گیرد. Max Pooling حداکثر مقدار پیکسل ها را در یک فیلتر (در یک نقطه در تصویر) به دست می آورد. با فرض استفاده از فیلترهای 2×2، این 3/4 اطلاعات را کاهش می دهد.
حداکثر مقادیر پیکسل ها به منظور در نظر گرفتن اعوجاج های احتمالی تصویر استفاده می شود و پارامترها/اندازه تصویر به منظور کنترل بیش از حد برازش کاهش می یابد. انواع دیگری مانند ادغام متوسط یا ادغام مجموع وجود دارد، اما این موارد به دفعات مورد استفاده قرار نمی گیرند زیرا حداکثر ادغام تمایل به ارائه دقت بهتر دارد.
صاف کردن
لایههای نهایی CNN ما، لایههای بهم پیوسته، مستلزم این است که دادهها به شکل یک بردار باشند تا پردازش شوند. به همین دلیل، داده ها باید “مسطح” شوند. مقادیر در یک بردار طولانی یا ستونی از اعداد مرتب شده به ترتیب فشرده می شوند.
لایه کاملا متصل
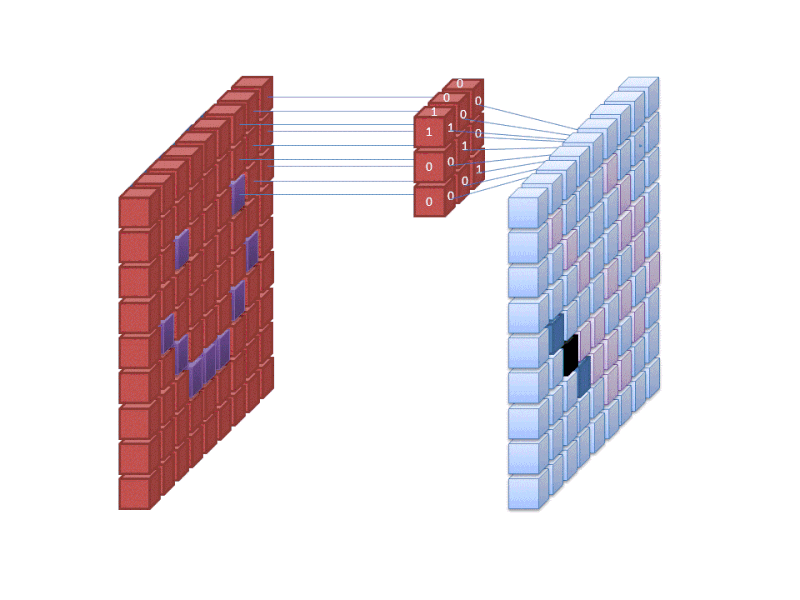
لایه های نهایی CNN لایه های متراکم متصل یا یک هستند شبکه های عصبی مصنوعی (ANN). وظیفه اصلی ANN تجزیه و تحلیل ویژگی های ورودی و ترکیب آنها به ویژگی های مختلف است که به طبقه بندی کمک می کند. این لایهها اساساً مجموعهای از نورونها را تشکیل میدهند که بخشهای مختلف جسم مورد نظر را نشان میدهند و مجموعهای از نورونها ممکن است گوشهای فلاپی سگ یا قرمزی یک سیب را نشان دهند. هنگامی که تعداد زیادی از این نورون ها در پاسخ به یک تصویر ورودی فعال شوند، تصویر به عنوان یک شی طبقه بندی می شود.

اعتبار: commons.wikimedia.org
خطا یا تفاوت بین مقادیر محاسبه شده و مقدار مورد انتظار در مجموعه آموزشی، توسط ANN محاسبه می شود. شبکه سپس تحت پس انتشار، جایی که تأثیر یک نورون معین است روی یک نورون در لایه بعدی محاسبه شده و تأثیر آن تنظیم می شود. این کار برای بهینه سازی عملکرد مدل انجام می شود. این process سپس بارها و بارها تکرار می شود. این روش آموزش شبکه است روی داده ها و ارتباط بین ویژگی های ورودی و کلاس های خروجی را یاد می گیرد.
نورونهای لایههای کاملاً متصل میانی مقادیر باینری مربوط به کلاسهای ممکن را خروجی میدهند. اگر چهار کلاس مختلف دارید (مثلاً یک سگ، یک ماشین، یک خانه و یک شخص)، نورون برای کلاسی که تصور میکند تصویر نشاندهنده آن است مقدار “1” و برای کلاسهای دیگر مقدار “0” خواهد داشت. .
لایه نهایی کاملا متصل خروجی لایه قبل از خود را دریافت می کند و یک احتمال برای هر یک از کلاس ها ارائه می دهد که به یک جمع می شود. اگر مقدار 0.75 در دسته “سگ” وجود داشته باشد، 75٪ اطمینان را نشان می دهد که تصویر یک سگ است.
طبقهبندیکننده تصویر اکنون آموزش دیده است، و تصاویر را میتوان به سیانان منتقل کرد، که اکنون در مورد محتوای آن تصویر حدس میزند.
گردش کار یادگیری ماشین
قبل از اینکه به مثالی از آموزش یک طبقهبندی کننده تصویر بپردازیم، اجازه دهید لحظهای را به درک گردش کار یا خط لوله یادگیری ماشین اختصاص دهیم. را process برای آموزش یک مدل شبکه عصبی نسبتاً استاندارد است و می تواند به چهار فاز مختلف تقسیم شود.
آماده سازی داده ها
ابتدا باید داده های خود را جمع آوری کرده و در فرمی قرار دهید که شبکه بتواند آموزش دهد روی. این شامل جمع آوری تصاویر و برچسب زدن آنها است. حتی اگر مجموعه داده ای را دانلود کرده باشید که شخص دیگری آماده کرده است، احتمالاً وجود دارد پیش پردازش یا آماده سازی که باید قبل از استفاده از آن برای آموزش انجام دهید. آماده سازی داده ها یک هنر است روی مربوط به مواردی مانند مقادیر از دست رفته، داده های خراب، داده هایی با فرمت اشتباه، برچسب های نادرست و غیره است.
در این مقاله از مجموعه داده های پیش پردازش شده استفاده خواهیم کرد.
ایجاد مدل
ایجاد مدل شبکه عصبی شامل انتخاب پارامترها و فراپارامترهای مختلف است. شما باید در مورد تعداد لایه هایی که در مدل خود استفاده می کنید، اندازه ورودی و خروجی لایه ها، نوع توابع فعال سازی، اینکه آیا از انصراف استفاده می کنید یا نه و غیره تصمیم بگیرید.
یادگیری اینکه از کدام پارامترها و فراپارامترها استفاده کنید با گذشت زمان (و مطالعه زیاد) به دست میآید، اما در خارج از دروازه، برخی از اکتشافیها وجود دارد که میتوانید از آنها برای راهاندازی شما استفاده کنید و ما برخی از آنها را در طول مثال پیادهسازی پوشش خواهیم داد.
آموزش مدل
بعد از اینکه مدل خود را ایجاد کردید، به سادگی یک نمونه از مدل ایجاد کرده و آن را با داده های آموزشی خود مطابقت دهید. بزرگترین نکته در هنگام آموزش یک مدل، مدت زمانی است که مدل برای آموزش میگیرد. شما می توانید با تعیین تعداد دوره های آموزشی برای یک شبکه، مدت زمان آموزش را مشخص کنید. هر چه مدت زمان بیشتری به یک مدل آموزش دهید، عملکرد آن بیشتر می شود، اما دوره های تمرینی زیاد و شما در معرض خطر بیش از حد برازش قرار می گیرید.
انتخاب تعداد دورهها برای تمرین چیزی است که احساس میکنید، و مرسوم است که وزنهای یک شبکه را در بین جلسات تمرینی ذخیره کنید تا بعد از پیشرفت در آموزش شبکه، نیازی به شروع مجدد نداشته باشید.
ارزیابی مدل
چندین مرحله برای ارزیابی مدل وجود دارد. اولین گام در ارزیابی مدل، مقایسه عملکرد مدل در برابر a است مجموعه داده اعتبارسنجی، مجموعه داده ای که مدل آموزش ندیده است روی. شما عملکرد مدل را با این مجموعه اعتبارسنجی مقایسه کرده و عملکرد آن را از طریق معیارهای مختلف تجزیه و تحلیل خواهید کرد.
وجود دارد معیارهای مختلف برای تعیین عملکرد یک مدل شبکه عصبی، اما رایج ترین معیار “دقت” است، مقدار تصاویر طبقه بندی شده به درستی بر تعداد کل تصاویر در مجموعه داده شما تقسیم می شود.
بعد از اینکه دقت عملکرد مدل را دیدید روی آ مجموعه داده اعتبارسنجی، معمولاً به عقب باز می گردید و شبکه را با استفاده از پارامترهای کمی تغییر یافته آموزش می دهید، زیرا بعید است که در اولین باری که تمرین می کنید از عملکرد شبکه خود راضی باشید. شما همچنان پارامترهای شبکه خود را تغییر می دهید، آن را دوباره آموزش می دهید و عملکرد آن را اندازه می گیرید تا زمانی که از دقت شبکه راضی باشید.
در نهایت، عملکرد شبکه را آزمایش خواهید کرد روی آ مجموعه تست. این مجموعه آزمایشی مجموعه دیگری از داده هایی است که مدل شما قبلاً ندیده است.
شاید از خود می پرسید:
چرا با مجموعه تست زحمت بکشید؟ اگر ایده ای از دقت مدل خود دارید، آیا هدف از مجموعه اعتبار سنجی این نیست؟
این ایده خوبی است که مجموعه ای از داده هایی را که شبکه هرگز ندیده است برای آزمایش نگه دارید زیرا تمام تغییرات پارامترهایی که انجام می دهید همراه با آزمایش مجدد است. روی مجموعه اعتبار سنجی، می تواند به این معنی باشد که شبکه شما برخی از ویژگی های خاص مجموعه اعتبار سنجی را آموخته است که به داده های خارج از نمونه تعمیم نمی یابد.
بنابراین، هدف مجموعه تست بررسی مسائلی مانند بیش از حد برازش و اطمینان بیشتر از اینکه مدل شما واقعاً برای عملکرد در دنیای واقعی مناسب است، است.
تشخیص/طبقه بندی تصویر با CNN در کراس
ما تاکنون موارد زیادی را پوشش دادهایم، و اگر همه این اطلاعات کمی طاقتفرسا بوده است، دیدن این مفاهیم در یک طبقهبندیکننده نمونه آموزش دیده گرد هم آمدهاند. روی یک مجموعه داده باید این مفاهیم را ملموس تر کند. بنابراین بیایید به یک مثال کامل از تشخیص تصویر با Keras نگاه کنیم، از بارگذاری داده ها تا ارزیابی.

اعتبار: www.cs.toronto.edu
برای شروع، ما به یک مجموعه داده برای آموزش نیاز داریم روی. در این مثال از معروف استفاده خواهیم کرد CIFAR-10 مجموعه داده CIFAR-10 یک مجموعه داده تصویری بزرگ است که شامل بیش از 60000 تصویر است که نشان دهنده 10 کلاس مختلف از اشیا مانند گربه ها، هواپیماها و اتومبیل ها است.
تصاویر RGB تمام رنگی هستند، اما نسبتا کوچک هستند، فقط 32 x 32. یک چیز عالی در مورد مجموعه داده CIFAR-10 این است که با Keras بسته بندی شده است، بنابراین بارگذاری مجموعه داده ها و تصاویر مورد نیاز بسیار آسان است. پیش پردازش بسیار کم
اولین کاری که باید انجام دهیم این است import کتابخانه های لازم من نشان خواهم داد که چگونه از این واردات استفاده می شود، اما در حال حاضر بدانید که ما از NumPy و ماژول های مختلف مرتبط با Keras استفاده خواهیم کرد:
import numpy
from tensorflow import keras
from keras.constraints import maxnorm
from keras.utils import np_utils
ما در اینجا از یک دانه تصادفی استفاده می کنیم تا نتایج به دست آمده در این مقاله توسط شما تکرار شود، به همین دلیل است که ما نیاز داریم numpy:
seed = 21
آماده سازی داده ها
ما به یکی دیگر نیاز داریم import: مجموعه داده
from keras.datasets import cifar10
حالا بیایید مجموعه داده را بارگذاری کنیم. ما می توانیم این کار را به سادگی با تعیین متغیرهایی که می خواهیم داده ها را در آنها بارگذاری کنیم و سپس با استفاده از آن انجام دهیم load_data() تابع:
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
در بیشتر موارد، برای آماده سازی داده های خود نیاز به پیش پردازشی دارید، اما از آنجایی که ما از یک مجموعه داده از پیش بسته بندی شده استفاده می کنیم، پیش پردازش بسیار کمی باید انجام شود. یکی از کارهایی که می خواهیم انجام دهیم عادی سازی داده های ورودی است.
اگر مقادیر داده های ورودی در محدوده بسیار وسیعی باشند، می تواند بر روش عملکرد شبکه تأثیر منفی بگذارد. در این حالت مقادیر ورودی پیکسل های موجود در تصویر هستند که مقداری بین 0 تا 255 دارند.
بنابراین برای عادی سازی داده ها، می توانیم به سادگی مقادیر تصویر را بر 255 تقسیم کنیم. برای این کار ابتدا باید داده ها را از نوع شناور درآوریم، زیرا آنها در حال حاضر اعداد صحیح هستند. ما می توانیم این کار را با استفاده از astype() دستور NumPy و سپس اعلام نوع داده ای که می خواهیم:
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train = X_train / 255.0
X_test = X_test / 255.0
کار دیگری که باید انجام دهیم تا داده ها را برای شبکه آماده کنیم این است که یک کدگذاری داغ ارزش ها. من در اینجا به جزئیات رمزگذاری تک داغ نمی پردازم، اما فعلاً بدانید که تصاویر را نمی توان به همان شکلی که هستند توسط شبکه استفاده کرد، ابتدا باید کدگذاری شوند و بهترین استفاده از رمزگذاری تک داغ در هنگام انجام است. طبقه بندی باینری
ما در اینجا به طور موثر طبقهبندی باینری را انجام میدهیم، زیرا یک تصویر یا به یک کلاس تعلق دارد یا به یک کلاس تعلق ندارد، نمیتواند جایی در این بین قرار گیرد. دستور NumPy to_categorical() برای رمزگذاری یکباره استفاده می شود. به همین دلیل ما آن را وارد کردیم np_utils تابع Keras، همانطور که در آن موجود است to_categorical().
ما همچنین باید تعداد کلاسهایی را که در مجموعه داده هستند مشخص کنیم، بنابراین میدانیم چند نورون باید لایه نهایی را فشرده کنیم:
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
class_num = y_test.shape(1)
طراحی مدل
ما به مرحله ای رسیده ایم که مدل CNN را طراحی می کنیم. اولین کاری که باید انجام دهیم این است که قالبی را که می خواهیم برای مدل استفاده کنیم، تعریف کنیم. Keras چندین فرمت یا طرح اولیه برای ساخت مدل دارد روی، ولی Sequential پرکاربردترین است و به همین دلیل آن را از کراس وارد کرده ایم.
مدل را ایجاد کنید
میتوانیم با ایجاد یک نمونه خالی و سپس افزودن لایهها به آن، مدل ترتیبی را بسازیم:
model = Sequential()
model.add(keras.layers.layer1)
model.add(keras.layers.layer2)
model.add(keras.layers.layer3)
یا، می توانیم در هر لایه به عنوان یک عنصر در لیستی در قسمت ارسال کنیم Sequential() تماس سازنده:
model = keras.Sequential((
keras.layers.layer1,
keras.layers.layer2,
keras.layers.layer3
))
لایه اول مدل ما یک لایه کانولوشن است. ورودی ها را می گیرد و فیلترهای کانولوشنال را اجرا می کند روی آنها را
هنگام پیادهسازی این موارد در Keras، باید تعداد کانالها/فیلترهایی را که میخواهیم (که 32 مورد زیر است)، اندازه فیلتر مورد نظر (در این مورد 3×3)، شکل ورودی (هنگام ایجاد لایه اول) را مشخص کنیم. ) و فعال سازی و padding مورد نیاز ما. اینها همه فراپارامترهایی در CNN هستند که مستعد تنظیم هستند. همانطور که اشاره شد، relu رایج ترین فعال سازی است و padding='same' فقط به این معنی است که ما اصلاً اندازه تصویر را تغییر نمی دهیم. می توانید سایر لایه های فعال سازی را نیز امتحان کنید – هرچند، relu یک پیشفرض بسیار معقول برای آزمایش قبل از تنظیم است:
model = keras.Sequential()
model.add(keras.layers.Conv2D(32, (3, 3), input_shape=X_train.shape(1:), padding='same'))
model.add(keras.layers.Activation('relu'))
توجه داشته باشید: از آنجایی که یک فعال سازی لایه تقریباً بعد از همه لایه ها وجود دارد، می توانید به جای آن آن را به عنوان آرگومان رشته ای به لایه قبلی اضافه کنید. Keras به طور خودکار یک لایه فعال سازی اضافه می کند و این رویکرد معمولاً خواناتر است.
model.add(keras.layers.Conv2D(32, 3, input_shape=(32, 32, 3), activation='relu', padding='same'))
اکنون یک لایه dropout اضافه می کنیم تا از برازش بیش از حد جلوگیری کنیم که با حذف تصادفی برخی از اتصالات بین لایه ها عمل می کند.0.2 به این معنی که 20٪ از اتصالات موجود را کاهش می دهد):
model.add(keras.layers.Dropout(0.2))
همچنین ممکن است بخواهیم نرمال سازی دسته ای را در اینجا اضافه کنیم. عادی سازی دسته ای ورودی های وارد شده به لایه بعدی را عادی می کند و اطمینان حاصل می کند که شبکه همیشه با همان توزیع مورد نظر ما فعال سازی ایجاد می کند:
model.add(keras.layers.BatchNormalization())
این اساسی است مسدود کردن برای ساخت CNN استفاده می شود. لایه کانولوشن، فعال سازی، ترک تحصیل، ادغام. اینها بلوک ها سپس می توان از نظر پیچیدگی، معمولاً در یک الگوی هرمی روی هم قرار داد. بلوک بعدی معمولاً حاوی یک لایه کانولوشن با یک فیلتر بزرگتر است که به آن اجازه می دهد تا الگوها را با جزئیات بیشتر پیدا کند و بیشتر انتزاع کند و به دنبال آن یک لایه ادغام، حذف و نرمال سازی دسته ای ایجاد شود:
model.add(keras.layers.Conv2D(64, 3, activation='relu', padding='same'))
model.add(keras.layers.MaxPooling2D(2))
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.BatchNormalization())
میتوانید تعداد دقیق لایههای کانولوشن را به دلخواه تغییر دهید، اگرچه هر کدام هزینههای محاسباتی بیشتری را اضافه میکنند. توجه داشته باشید که با اضافه کردن لایههای کانولوشن، معمولاً تعداد فیلترهای آنها را افزایش میدهید تا مدل بتواند نمایشهای پیچیدهتری را بیاموزد. اگر اعداد انتخاب شده برای این لایه ها تا حدودی دلخواه به نظر می رسند، به طور کلی، فیلترها را هر چه پیش می روید افزایش می دهید روی و توصیه می شود که آنها را با قدرت 2 بسازید که می تواند در هنگام تمرین سود جزئی داشته باشد روی یک GPU
مهم است که لایه های ادغام بیش از حد نداشته باشید، زیرا هر لایه ادغام برخی از داده ها را با کاهش ابعاد ورودی با یک فاکتور معین دور می کند. در مورد ما، تصاویر را برش می دهد به نصف. ادغام بیش از حد اغلب منجر به این می شود که تقریباً هیچ چیز برای لایه های متصل متراکم وجود نداشته باشد که در مورد زمانی که داده ها به آنها می رسد یاد بگیرند.
بسته به تعداد دقیق لایههای جمعآوری که باید استفاده کنید متفاوت است روی وظیفهای که انجام میدهید، و این چیزی است که در طول زمان احساس خواهید کرد. از آنجایی که تصاویر در اینجا بسیار کوچک هستند، ما بیش از دو بار جمع نمی کنیم.
اکنون میتوانید این لایهها را تکرار کنید تا به شبکهتان نمایشهای بیشتری بدهید تا از پس آن برآیند:
model.add(keras.layers.Conv2D(64, 3, activation='relu', padding='same'))
model.add(keras.layers.MaxPooling2D(2))
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Conv2D(128, 3, activation='relu', padding='same'))
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.BatchNormalization())
بعد از اینکه کار با لایه های کانولوشن تمام شد، باید Flatten داده ها، به همین دلیل است که تابع بالا را وارد کردیم. ما همچنین یک لایه ترک تحصیل دوباره اضافه می کنیم:
model.add(keras.layers.Flatten())
model.add(keras.layers.Dropout(0.2))
حالا ما از آن استفاده می کنیم Dense import و اولین لایه متصل متراکم را ایجاد کنید. باید تعداد نورون های لایه متراکم را مشخص کنیم. توجه داشته باشید که تعداد نورونها در لایههای بعدی کاهش مییابد و در نهایت به همان تعداد نورونهایی که در مجموعه دادهها وجود دارد (در این مورد 10) نزدیک میشود.
ما میتوانیم چندین لایه متراکم در اینجا داشته باشیم، و این لایهها اطلاعات را از نقشههای ویژگی استخراج میکنند تا طبقهبندی تصاویر را بر اساس آنها یاد بگیرند. روی نقشه های ویژگی از آنجایی که ما تصاویر نسبتاً کوچکی داریم که در نقشههای ویژگی نسبتاً کوچک فشرده شدهاند – نیازی به چند لایه متراکم نیست. یک لایه ساده و 32 نورونی باید کاملاً کافی باشد:
model.add(keras.layers.Dense(32, activation='relu'))
model.add(keras.layers.Dropout(0.3))
model.add(keras.layers.BatchNormalization())
توجه داشته باشید: مراقب لایه های متراکم باشید. از آنجایی که آنها کاملاً به هم متصل هستند، وجود تنها چند لایه در اینجا به جای یک لایه به طور قابل توجهی تعداد پارامترهای قابل یادگیری را به سمت بالا افزایش می دهد. به عنوان مثال، اگر سه لایه متراکم داشتیم (128، 64 و 32)، تعداد پارامترهای قابل آموزش در مقایسه با 400k در این مدل، به 2.3M افزایش می یابد. مدل بزرگتر در واقع حتی دقت کمتری داشت، علاوه بر زمانهای آموزشی طولانیتر در تستهای ما.
در لایه آخر، تعداد کلاس ها را برای تعداد نورون ها پاس می کنیم. هر نورون یک کلاس را نشان می دهد و خروجی این لایه یک بردار 10 نورونی خواهد بود که هر نورون احتمالی را ذخیره می کند که تصویر مورد نظر متعلق به کلاسی است که نشان می دهد.
در نهایت، softmax تابع فعال سازی نورونی را با بیشترین احتمال به عنوان خروجی انتخاب می کند و رای می دهد که تصویر به آن کلاس تعلق دارد:
model.add(keras.layers.Dense(class_num, activation='softmax'))
اکنون که مدلی را که می خواهیم استفاده کنیم طراحی کرده ایم، فقط باید آن را کامپایل کنیم. بهینه ساز چیزی است که وزن ها را در شبکه شما تنظیم می کند تا به نقطه کمترین تلفات نزدیک شود. را برآورد لحظه تطبیقی الگوریتم (آدام) یک بهینه ساز بسیار رایج و یک بهینه ساز پیش فرض بسیار معقول برای آزمایش است. معمولاً پایدار است و عملکرد خوبی دارد روی طیف گسترده ای از وظایف، بنابراین به احتمال زیاد در اینجا عملکرد خوبی خواهد داشت.
اگر اینطور نیست، میتوانیم به بهینهساز دیگری مانند نادام (آدام با شتاب نستروف)، RMSProp (اغلب برای رگرسیون استفاده می شود)، و غیره.
ما پیگیری خواهیم کرد دقت و دقت اعتبارسنجی تا مطمئن شویم که از تطبیق بیش از حد CNN به شدت جلوگیری می کنیم. اگر این دو به طور قابل توجهی شروع به واگرایی کنند و شبکه بسیار بهتر عمل کند روی مجموعه اعتبارسنجی – بیش از حد مناسب است.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=('accuracy', 'val_accuracy'))
ما میتوانیم print خلاصه مدل را بیاورید تا ببینید کل مدل چگونه به نظر می رسد.
print(model.summary())
چاپ خلاصه اطلاعات کمی را در اختیار ما قرار می دهد و می توان از آن برای بررسی متقابل معماری خود با آنچه در راهنما آمده است استفاده کرد:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_43 (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
dropout_50 (Dropout) (None, 32, 32, 32) 0
_________________________________________________________________
batch_normalization_44 (Batc (None, 32, 32, 32) 128
_________________________________________________________________
conv2d_44 (Conv2D) (None, 32, 32, 64) 18496
_________________________________________________________________
max_pooling2d_20 (MaxPooling (None, 16, 16, 64) 0
_________________________________________________________________
dropout_51 (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
batch_normalization_45 (Batc (None, 16, 16, 64) 256
_________________________________________________________________
conv2d_45 (Conv2D) (None, 16, 16, 64) 36928
_________________________________________________________________
max_pooling2d_21 (MaxPooling (None, 8, 8, 64) 0
_________________________________________________________________
dropout_52 (Dropout) (None, 8, 8, 64) 0
_________________________________________________________________
batch_normalization_46 (Batc (None, 8, 8, 64) 256
_________________________________________________________________
conv2d_46 (Conv2D) (None, 8, 8, 128) 73856
_________________________________________________________________
dropout_53 (Dropout) (None, 8, 8, 128) 0
_________________________________________________________________
batch_normalization_47 (Batc (None, 8, 8, 128) 512
_________________________________________________________________
flatten_6 (Flatten) (None, 8192) 0
_________________________________________________________________
dropout_54 (Dropout) (None, 8192) 0
_________________________________________________________________
dense_18 (Dense) (None, 32) 262176
_________________________________________________________________
dropout_55 (Dropout) (None, 32) 0
_________________________________________________________________
batch_normalization_48 (Batc (None, 32) 128
_________________________________________________________________
dense_19 (Dense) (None, 10) 330
=================================================================
Total params: 393,962
Trainable params: 393,322
Non-trainable params: 640
حالا به آموزش مدل میرسیم. برای انجام این کار، تنها کاری که باید انجام دهیم این است که با شماره تماس بگیرید fit() تابع روی مدل و پاس در پارامترهای انتخاب شده. علاوه بر این، میتوانیم تاریخچه آن را نیز ذخیره کنیم و عملکرد آن را در طول آموزش ترسیم کنیم process. این اغلب اطلاعات ارزشمندی به ما می دهد روی پیشرفتی که شبکه داشته است، و اینکه آیا میتوانستیم آن را بیشتر آموزش دهیم و آیا در صورت انجام این کار، شروع به نصب بیش از حد خواهد کرد یا خیر.
ما از یک دانه برای تکرارپذیری استفاده کرده ایم، بنابراین بیایید شبکه را آموزش دهیم و عملکرد آن را ذخیره کنیم:
numpy.random.seed(seed)
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=25, batch_size=64)
این نتیجه در:
Epoch 1/25
782/782 (==============================) - 12s 15ms/step - loss: 1.4851 - accuracy: 0.4721 - val_loss: 1.1805 - val_accuracy: 0.5777
...
Epoch 25/25
782/782 (==============================) - 11s 14ms/step - loss: 0.4154 - accuracy: 0.8538 - val_loss: 0.5284 - val_accuracy: 0.8197
توجه داشته باشید که در بیشتر موارد، شما می خواهید یک مجموعه اعتبار سنجی متفاوت از مجموعه آزمایشی داشته باشید، بنابراین درصدی از داده های آموزشی را برای استفاده به عنوان مجموعه اعتبار سنجی تعیین می کنید. در این مورد، ما فقط داده های آزمون را پاس می کنیم تا مطمئن شویم که داده های آزمون کنار گذاشته شده و آموزش داده نشده است روی. ما فقط داده های آزمایشی را در این مثال خواهیم داشت تا همه چیز ساده باشد.
حالا میتوانیم مدل را ارزیابی کنیم و ببینیم که چگونه کار میکند. فقط تماس بگیرید model.evaluate():
scores = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores(1)*100))
و ما با نتیجه استقبال می کنیم:
Accuracy: 82.01%
با Transfer Learning و معماری های قدرتمندتر، می توانید به چیزهای بیشتری دست پیدا کنید. ما دقت 94% را در راهنمای خود برای طبقهبندی تصویر با آموزش انتقال در Keras نشان میدهیم – مدلهای پیشرفته CNN ایجاد کنید!
علاوه بر این، ما می توانیم تاریخچه را به راحتی تجسم کنیم:
import pandas as pd
import matplotlib.pyplot as plt
pd.DataFrame(history.history).plot()
plt.show()
این نتیجه در:

از روی منحنیها، میتوانیم ببینیم که آموزش واقعاً پس از 25 دوره متوقف نشده است – احتمالاً میتوانست پیش برود. روی برای مدت طولانی تر از آن روی همین مدل و معماری، که دقت بالاتری را به همراه داشت.
و بس! ما اکنون یک CNN تشخیص تصویر آموزش دیده داریم. برای اولین اجرا بد نیست، اما احتمالاً می خواهید با ساختار و پارامترهای مدل بازی کنید تا ببینید آیا نمی توانید عملکرد بهتری داشته باشید.
نتیجه
اکنون که اولین شبکه تشخیص تصویر خود را در Keras پیادهسازی کردهاید، ایده خوبی است که با مدل بازی کنید و ببینید که چگونه تغییر پارامترهای آن بر عملکرد آن تأثیر میگذارد.
این به شما شهودی در مورد بهترین انتخاب ها برای پارامترهای مختلف مدل می دهد. شما هم باید مطالعه کنید روی پارامترهای مختلف و گزینه های فراپارامتر در حالی که شما این کار را انجام می دهید. بعد از اینکه با این موارد راحت شدید، می توانید طبقه بندی کننده تصویر خود را پیاده سازی کنید روی یک مجموعه داده متفاوت
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-22 16:29:04
