از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
این یازدهمین مقاله من از سری مقالات است روی پایتون برای NLP و مقاله دوم روی کتابخانه Gensim در این مجموعه. در مقاله قبلی، معرفی مختصری از کتابخانه Gensim پایتون ارائه دادم. من توضیح دادم که چگونه میتوانیم فرهنگهای لغت ایجاد کنیم که کلمات را به شناسههای عددی متناظرشان نگاشت میکنند. ما بیشتر در مورد چگونگی ایجاد مجموعه ای از کلمات از فرهنگ لغت بحث کردیم. در این مقاله به بررسی روش مدل سازی موضوع با استفاده از کتابخانه Gensim می پردازیم.
روش انجام مدلسازی موضوع با استفاده از کتابخانه Scikit-Learn پایتون را در مقاله قبلی خود توضیح دادهام. در آن مقاله روش انجام آن را توضیح دادم تخصیص دیریکله نهفته (LDA) و فاکتورسازی ماتریس غیر منفی (NMF) را می توان برای مدل سازی موضوع استفاده کرد.
در این مقاله از کتابخانه Gensim برای مدل سازی موضوع استفاده خواهیم کرد. رویکردهای مورد استفاده برای مدلسازی موضوع، LDA و LSI (نمایه سازی معنایی نهفته).
نصب کتابخانه های مورد نیاز
ما مدل سازی موضوع را انجام خواهیم داد روی متن به دست آمده از مقالات ویکی پدیا. برای خراش دادن مقالات ویکیپدیا، از API ویکیپدیا استفاده میکنیم. برای دانلود کتابخانه API ویکیپدیا، دستور زیر را اجرا کنید:
$ pip install wikipedia
در غیر این صورت، اگر از توزیع Anaconda پایتون استفاده می کنید، می توانید از یکی از دستورات زیر استفاده کنید:
$ conda install -c conda-forge wikipedia
$ conda install -c conda-forge/label/cf201901 wikipedia
برای تجسم مدل موضوع خود، از آن استفاده خواهیم کرد pyLDAvis کتابخانه برای دانلود کتابخانه موارد زیر را اجرا کنید pip دستور:
$ pip install pyLDAvis
دوباره، اگر به جای آن از توزیع Anaconda استفاده کنید، می توانید یکی از دستورات زیر را اجرا کنید:
$ conda install -c conda-forge pyldavis
$ conda install -c conda-forge/label/gcc7 pyldavis
$ conda install -c conda-forge/label/cf201901 pyldavis
مدل سازی موضوع با LDA
در این بخش، مدلسازی موضوعی مقالات ویکیپدیا را با استفاده از LDA انجام میدهیم.
چهار مقاله ویکی پدیا را دانلود خواهیم کرد روی موضوعات “گرمایش جهانی”، “هوش مصنوعی”، “برج ایفل” و “مونالیزا”. در مرحله بعد، مقالات را پیش پردازش می کنیم و سپس مرحله مدل سازی موضوع را دنبال می کنیم. در نهایت، خواهیم دید که چگونه می توانیم مدل LDA را تجسم کنیم.
خراش دادن مقالات ویکی پدیا
اسکریپت زیر را اجرا کنید:
import wikipedia
import nltk
nltk.download('stopwords')
en_stop = set(nltk.corpus.stopwords.words('english'))
global_warming = wikipedia.page("Global Warming")
artificial_intelligence = wikipedia.page("Artificial Intelligence")
mona_lisa = wikipedia.page("Mona Lisa")
eiffel_tower = wikipedia.page("Eiffel Tower")
corpus = (global_warming.content, artificial_intelligence.content, mona_lisa.content, eiffel_tower.content)
در اسکریپت بالا، ما ابتدا import را wikipedia و nltk کتابخانه ها انگلیسی را هم دانلود می کنیم nltk کلمات توقف بعداً از این کلمات توقف استفاده خواهیم کرد.
در مرحله بعد، مقاله را از ویکیپدیا با تعیین موضوع دانلود کردیم page موضوع از wikipedia کتابخانه شیء برگشتی حاوی اطلاعاتی در مورد دانلود شده است page.
برای بازیابی محتویات صفحه وب، می توانیم از content صفت. محتوای هر چهار مقاله در لیست نامگذاری شده ذخیره می شود corpus.
پیش پردازش داده ها
برای انجام مدلسازی موضوع از طریق LDA، به دیکشنری داده و مجموعه کلمات نیاز داریم. از آخرین مقاله (پیوند بالا)، می دانیم که برای ایجاد فرهنگ لغت و مجموعه کلمات به داده هایی به شکل نشانه نیاز داریم.
علاوه بر این، ما باید مواردی مانند علائم نقطه گذاری را حذف کنیم و کلمات را از مجموعه داده خود متوقف کنیم. برای یکنواختی، تمام نشانه ها را به حروف کوچک تبدیل می کنیم و همچنین آنها را به صورت لماتیزه می کنیم. همچنین، تمام نشانه هایی که کمتر از 5 کاراکتر دارند را حذف می کنیم.
به اسکریپت زیر نگاه کنید:
import re
from nltk.stem import WordNetLemmatizer
stemmer = WordNetLemmatizer()
def preprocess_text(document):
document = re.sub(r'\W', ' ', str(document))
document = re.sub(r'\s+(a-zA-Z)\s+', ' ', document)
document = re.sub(r'\^(a-zA-Z)\s+', ' ', document)
document = re.sub(r'\s+', ' ', document, flags=re.I)
document = re.sub(r'^b\s+', '', document)
document = document.lower()
tokens = document.split()
tokens = (stemmer.lemmatize(word) for word in tokens)
tokens = (word for word in tokens if word not in en_stop)
tokens = (word for word in tokens if len(word) > 5)
return tokens
در اسکریپت بالا متدی به نام ایجاد می کنیم preprocess_text که یک سند متنی را به عنوان پارامتر می پذیرد. این روش از عملیات regex برای انجام کارهای مختلف استفاده می کند. بیایید به طور خلاصه آنچه را که در تابع بالا اتفاق می افتد مرور کنیم:
document = re.sub(r'\W', ' ', str(X(sen)))
خط بالا جایگزین تمام کاراکترها و اعداد خاص با یک فاصله می شود. با این حال، وقتی علائم نگارشی را حذف می کنید، کاراکترهای منفرد بدون معنی در متن ظاهر می شوند. به عنوان مثال، زمانی که شما علائم نگارشی را در متن جایگزین می کنید Eiffel's، کلمات Eiffel و s به نظر می رسد. اینجا s معنی ندارد، بنابراین باید آن را با فضا جایگزین کنیم. اسکریپت زیر این کار را انجام می دهد:
document = re.sub(r'\s+(a-zA-Z)\s+', ' ', document)
اسکریپت فوق فقط کاراکترهای تکی را در متن حذف می کند. برای حذف یک کاراکتر در ابتدای متن از کد زیر استفاده می شود.
document = re.sub(r'\^(a-zA-Z)\s+', ' ', document)
هنگامی که تک فاصله های متن را حذف می کنید، چندین فاصله خالی ظاهر می شوند. کد زیر چندین فضای خالی را با یک فاصله جایگزین می کند:
document = re.sub(r'\s+', ' ', document, flags=re.I)
وقتی یک سند را به صورت آنلاین خراش می دهید، یک رشته b اغلب به سند ضمیمه می شود که به معنای باینری بودن سند است. برای حذف پیشوند b، از اسکریپت زیر استفاده می شود:
document = re.sub(r'^b\s+', '', document)
بقیه روش خود توضیحی است. سند به حروف کوچک تبدیل می شود و سپس به توکن تقسیم می شود. نشانه ها به صورت لماتیزه می شوند و کلمات توقف حذف می شوند. در نهایت، تمام نشانه هایی که کمتر از پنج کاراکتر دارند نادیده گرفته می شوند. بقیه نشانه ها به تابع فراخوانی بازگردانده می شوند.
موضوعات مدلسازی
این بخش گوشت مقاله است. در اینجا خواهیم دید که چگونه می توان از تابع داخلی کتابخانه Gensim برای مدل سازی موضوع استفاده کرد. اما قبل از آن، ما باید مجموعهای از تمام نشانهها (کلمات) در چهار مقاله ویکیپدیا را ایجاد کنیم. به اسکریپت زیر نگاه کنید:
processed_data = ();
for doc in corpus:
tokens = preprocess_text(doc)
processed_data.append(tokens)
اسکریپت بالا مستقیم است. ما از طریق آن تکرار می کنیم corpus فهرستی که شامل چهار مقاله ویکی پدیا به صورت رشته ای است. در هر تکرار، سند را به preprocess_text روشی که قبلا ایجاد کردیم این روش نشانه هایی را برای آن سند خاص برمی گرداند. توکن ها در processed_data فهرست
در پایان از for حلقه همه نشانه های هر چهار مقاله در ذخیره می شوند processed_data فهرست اکنون میتوانیم از این فهرست برای ایجاد فرهنگ لغت و مجموعه کلمات متناظر استفاده کنیم. اسکریپت زیر این کار را انجام می دهد:
from gensim import corpora
gensim_dictionary = corpora.Dictionary(processed_data)
gensim_corpus = (gensim_dictionary.doc2bow(token, allow_update=True) for token in processed_data)
در مرحله بعد، فرهنگ لغت خود و همچنین مجموعه کیسه کلمات را با استفاده از ترشی ذخیره می کنیم. بعداً از فرهنگ لغت ذخیره شده برای پیش بینی استفاده خواهیم کرد روی داده های جدید
import pickle
pickle.dump(gensim_corpus, open('gensim_corpus_corpus.pkl', 'wb'))
gensim_dictionary.save('gensim_dictionary.gensim')
اکنون، ما همه چیز مورد نیاز برای ایجاد یک مدل LDA در Gensim را داریم. ما استفاده خواهیم کرد LdaModel کلاس از gensim.models.ldamodel ماژول برای ایجاد مدل LDA. ما باید پیکره کیسه کلمات را که قبلاً به عنوان پارامتر اول ایجاد کردیم به آن پاس دهیم LdaModel سازنده، به دنبال آن تعداد موضوعات، دیکشنری که قبلا ایجاد کردیم، و تعداد پاسها (تعداد تکرار برای مدل).
اسکریپت زیر را اجرا کنید:
import gensim
lda_model = gensim.models.ldamodel.LdaModel(gensim_corpus, num_topics=4, id2word=gensim_dictionary, passes=20)
lda_model.save('gensim_model.gensim')
بله آن به آن سادگی است. در اسکریپت بالا، مدل LDA را از مجموعه داده خود ایجاد کردیم و آن را ذخیره کردیم.
بعد، اجازه دهید print 10 کلمه برای هر موضوع. برای این کار می توانیم از print_topics روش. اسکریپت زیر را اجرا کنید:
topics = lda_model.print_topics(num_words=10)
for topic in topics:
print(topic)
خروجی به شکل زیر است:
(0, '0.036*"painting" + 0.018*"leonardo" + 0.009*"louvre" + 0.009*"portrait" + 0.006*"museum" + 0.006*"century" + 0.006*"french" + 0.005*"giocondo" + 0.005*"original" + 0.004*"picture"')
(1, '0.016*"intelligence" + 0.014*"machine" + 0.012*"artificial" + 0.011*"problem" + 0.010*"learning" + 0.009*"system" + 0.008*"network" + 0.007*"research" + 0.007*"knowledge" + 0.007*"computer"')
(2, '0.026*"eiffel" + 0.008*"second" + 0.006*"french" + 0.006*"structure" + 0.006*"exposition" + 0.005*"tallest" + 0.005*"engineer" + 0.004*"design" + 0.004*"france" + 0.004*"restaurant"')
(3, '0.031*"climate" + 0.026*"change" + 0.024*"warming" + 0.022*"global" + 0.014*"emission" + 0.013*"effect" + 0.012*"greenhouse" + 0.011*"temperature" + 0.007*"carbon" + 0.006*"increase"')
مبحث اول شامل کلماتی مانند painting، louvre، portrait، french museumو غیره می توان فرض کرد که این کلمات متعلق به موضوعی است که مربوط به یک عکس با ارتباط فرانسوی است.
به طور مشابه، دوم حاوی کلماتی مانند intelligence، machine، researchو غیره می توان فرض کرد که این کلمات متعلق به مبحث مربوط به هوش مصنوعی است.
به همین ترتیب، کلمات از مبحث سوم و چهارم به این واقعیت اشاره دارد که این کلمات به ترتیب بخشی از مبحث برج ایفل و گرمایش جهانی هستند.
ما به وضوح می توانیم ببینیم که مدل LDA با موفقیت چهار موضوع را در مجموعه داده ما شناسایی کرده است.
ذکر این نکته ضروری است که LDA یک الگوریتم یادگیری بدون نظارت است و در مسائل دنیای واقعی، از قبل از موضوعات موجود در مجموعه داده اطلاعی نخواهید داشت. به سادگی یک مجموعه به شما داده می شود، موضوعات با استفاده از LDA ایجاد می شوند و سپس نام موضوعات به عهده شماست.
بیایید اکنون 8 موضوع را با استفاده از مجموعه داده خود ایجاد کنیم. ما خواهیم کرد print 5 کلمه در هر موضوع:
lda_model = gensim.models.ldamodel.LdaModel(gensim_corpus, num_topics=8, id2word=gensim_dictionary, passes=15)
lda_model.save('gensim_model.gensim')
topics = lda_model.print_topics(num_words=5)
for topic in topics:
print(topic)
خروجی به شکل زیر است:
(0, '0.000*"climate" + 0.000*"change" + 0.000*"eiffel" + 0.000*"warming" + 0.000*"global"')
(1, '0.018*"intelligence" + 0.016*"machine" + 0.013*"artificial" + 0.012*"problem" + 0.010*"learning"')
(2, '0.045*"painting" + 0.023*"leonardo" + 0.012*"louvre" + 0.011*"portrait" + 0.008*"museum"')
(3, '0.000*"intelligence" + 0.000*"machine" + 0.000*"problem" + 0.000*"artificial" + 0.000*"system"')
(4, '0.035*"climate" + 0.030*"change" + 0.027*"warming" + 0.026*"global" + 0.015*"emission"')
(5, '0.031*"eiffel" + 0.009*"second" + 0.007*"french" + 0.007*"structure" + 0.007*"exposition"')
(6, '0.000*"painting" + 0.000*"machine" + 0.000*"system" + 0.000*"intelligence" + 0.000*"problem"')
(7, '0.000*"climate" + 0.000*"change" + 0.000*"global" + 0.000*"machine" + 0.000*"intelligence"')
باز هم، تعداد موضوعاتی که می خواهید ایجاد کنید به شما بستگی دارد. تا زمانی که موضوعات مناسب را پیدا کنید، اعداد مختلف را امتحان کنید. برای مجموعه داده ما، تعداد مناسب موضوعات 4 است، زیرا از قبل می دانیم که مجموعه ما حاوی کلماتی از چهار مقاله مختلف است. با اجرای اسکریپت زیر به چهار مبحث برگردید:
lda_model = gensim.models.ldamodel.LdaModel(gensim_corpus, num_topics=4, id2word=gensim_dictionary, passes=20)
lda_model.save('gensim_model.gensim')
topics = lda_model.print_topics(num_words=10)
for topic in topics:
print(topic)
این بار، نتایج متفاوتی خواهید دید زیرا مقادیر اولیه برای پارامترهای LDA به صورت تصادفی انتخاب شده اند. نتایج این بار به شرح زیر است:
(0, '0.031*"climate" + 0.027*"change" + 0.024*"warming" + 0.023*"global" + 0.014*"emission" + 0.013*"effect" + 0.012*"greenhouse" + 0.011*"temperature" + 0.007*"carbon" + 0.006*"increase"')
(1, '0.026*"eiffel" + 0.008*"second" + 0.006*"french" + 0.006*"structure" + 0.006*"exposition" + 0.005*"tallest" + 0.005*"engineer" + 0.004*"design" + 0.004*"france" + 0.004*"restaurant"')
(2, '0.037*"painting" + 0.019*"leonardo" + 0.009*"louvre" + 0.009*"portrait" + 0.006*"museum" + 0.006*"century" + 0.006*"french" + 0.005*"giocondo" + 0.005*"original" + 0.004*"subject"')
(3, '0.016*"intelligence" + 0.014*"machine" + 0.012*"artificial" + 0.011*"problem" + 0.010*"learning" + 0.009*"system" + 0.008*"network" + 0.007*"knowledge" + 0.007*"research" + 0.007*"computer"')
می بینید که کلمات مربوط به مبحث اول در حال حاضر بیشتر مربوط به گرمایش جهانی است، در حالی که موضوع دوم حاوی کلمات مربوط به برج ایفل است.
ارزیابی مدل LDA
همانطور که قبلاً گفتم، ارزیابی مدلهای یادگیری بدون نظارت سخت است، زیرا هیچ حقیقت مشخصی وجود ندارد که بتوانیم خروجی مدل خود را در برابر آن آزمایش کنیم.
فرض کنید یک سند متنی جدید داریم و میخواهیم موضوع آن را با استفاده از مدل LDA که ایجاد کردیم پیدا کنیم، میتوانیم این کار را با استفاده از اسکریپت زیر انجام دهیم:
test_doc = 'Great structures are built to remember an event that happened in history.'
test_doc = preprocess_text(test_doc)
bow_test_doc = gensim_dictionary.doc2bow(test_doc)
print(lda_model.get_document_topics(bow_test_doc))
در اسکریپت بالا، یک رشته ایجاد کردیم، نمایش فرهنگ لغت آن را ایجاد کردیم و سپس رشته را به پیکره ba- of-words تبدیل کردیم. سپس نمایش کیسه کلمات به قسمت ارسال می شود get_document_topics روش. خروجی به شکل زیر است:
((0, 0.08422605), (1, 0.7446843), (2, 0.087012805), (3, 0.08407689))
خروجی نشان می دهد که احتمال 8.4% وجود دارد که سند جدید متعلق به مبحث 1 باشد (کلمات موضوع 1 را در آخرین خروجی ببینید). به همین ترتیب، 74.4 درصد احتمال دارد که این سند به موضوع دوم تعلق داشته باشد. اگر به مبحث دوم نگاه کنیم، حاوی کلمات مربوط به برج ایفل است. سند آزمون ما همچنین حاوی کلمات مربوط به سازه ها و ساختمان ها است. لذا مبحث دوم به آن اختصاص یافته است.
روش دیگر برای ارزیابی مدل LDA از طریق گیجی و امتیاز انسجام.
به عنوان یک قانون کلی برای یک مدل LDA خوب، امتیاز گیجی باید کم باشد در حالی که انسجام باید زیاد باشد. کتابخانه Gensim دارای یک CoherenceModel کلاس که می تواند برای یافتن انسجام مدل LDA استفاده شود. برای حیرت، LdaModel شی شامل log_perplexity روشی که یک پیکره از کلمات را به عنوان پارامتر می گیرد و گیجی مربوطه را برمی گرداند.
print('\nPerplexity:', lda_model.log_perplexity(gensim_corpus))
from gensim.models import CoherenceModel
coherence_score_lda = CoherenceModel(model=lda_model, texts=processed_data, dictionary=gensim_dictionary, coherence='c_v')
coherence_score = coherence_score_lda.get_coherence()
print('\nCoherence Score:', coherence_score)
را CoherenceModel کلاس مدل LDA، متن نشانه گذاری شده، فرهنگ لغت و دیکشنری را به عنوان پارامتر می گیرد. برای به دست آوردن نمره انسجام، get_coherence روش استفاده می شود. خروجی به شکل زیر است:
Perplexity: -7.492867099178969
Coherence Score: 0.718387005948207
تجسم LDA
برای تجسم داده های خود، می توانیم از آن استفاده کنیم pyLDAvis کتابخانه ای که در ابتدای مقاله دانلود کردیم. این کتابخانه شامل یک ماژول برای مدل Gensim LDA است. ابتدا باید با ارسال فرهنگ لغت، مجموعه ای از کلمات و مدل LDA، تجسم را آماده کنیم. prepare روش. در مرحله بعد، باید با آن تماس بگیریم display روی را gensim ماژول از pyLDAvis کتابخانه، مطابق شکل زیر:
gensim_dictionary = gensim.corpora.Dictionary.load('gensim_dictionary.gensim')
gensim_corpus = pickle.load(open('gensim_corpus_corpus.pkl', 'rb'))
lda_model = gensim.models.ldamodel.LdaModel.load('gensim_model.gensim')
import pyLDAvis.gensim
lda_visualization = pyLDAvis.gensim.prepare(lda_model, gensim_corpus, gensim_dictionary, sort_topics=False)
pyLDAvis.display(lda_visualization)
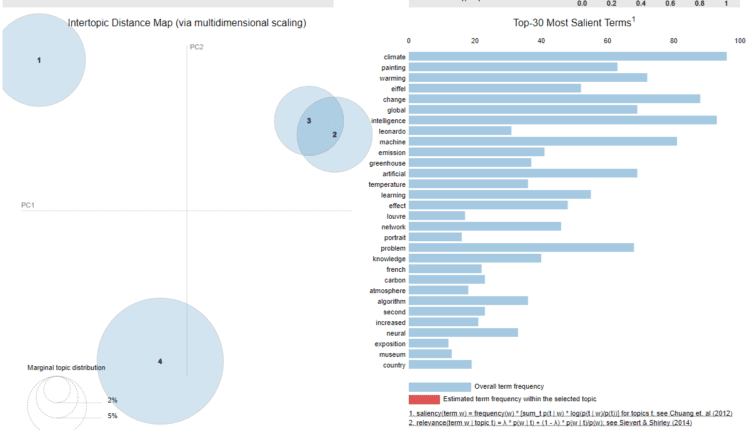
در خروجی تصویر زیر را مشاهده خواهید کرد:
 1")
هر دایره در تصویر بالا مربوط به یک موضوع است. از خروجی مدل LDA با استفاده از 4 مبحث می دانیم که مبحث اول مربوط به گرمایش جهانی، مبحث دوم مربوط به برج ایفل، مبحث سوم مربوط به مونالیزا و مبحث چهارم مربوط به موضوع مصنوعی است. هوش.
فاصله بین دایره ها نشان می دهد که موضوعات چقدر با یکدیگر متفاوت هستند. می بینید که دایره های 2 و 3 با هم همپوشانی دارند. این به این دلیل است که مبحث 2 (برج ایفل) و مبحث 3 (مونالیزا) کلمات مشترک زیادی دارند مانند “فرانسه”، “فرانسه”، “موزه”، “پاریس” و غیره.
اگر ماوس را روی هر کلمه ای نگه دارید روی در سمت راست، فقط دایره موضوعی را خواهید دید که حاوی کلمه است. به عنوان مثال، اگر ماوس را روی کلمه “اقلیم” نگه دارید، خواهید دید که مبحث 2 و 4 ناپدید می شوند زیرا حاوی کلمه اقلیم نیستند. حجم مبحث 1 افزایش خواهد یافت زیرا بیشتر موارد استفاده از کلمه “اقلیم” در مبحث اول است. درصد بسیار کمی در مبحث 3 است که در تصویر زیر نشان داده شده است:
 2")
به طور مشابه، اگر روی هر یک از حلقهها کلیک کنید، فهرستی از رایجترین اصطلاحات برای آن موضوع ظاهر میشود روی حق همراه با فراوانی وقوع در همین موضوع. به عنوان مثال، اگر ماوس را روی دایره 2 که مربوط به موضوع “برج ایفل” است قرار دهید، نتایج زیر را مشاهده خواهید کرد:
 3")
از خروجی می بینید که دایره موضوع دوم یعنی «برج ایفل» انتخاب شده است. از لیست روی درست است، شما می توانید رایج ترین اصطلاحات برای موضوع را ببینید. اصطلاح “ایفل” است روی بالاترین. همچنین، بدیهی است که اصطلاح «ایفل» بیشتر در این موضوع وجود داشته است.
از طرف دیگر، اگر به اصطلاح “فرانسوی” نگاه کنید، به وضوح می توانید ببینید که حدود نیمی از رخدادهای این اصطلاح در این موضوع است. این به این دلیل است که مبحث 3، یعنی “مونالیزا” نیز چندین بار عبارت “فرانسوی” را در خود دارد. برای تأیید این مورد، کلیک کنید روی دایره برای مبحث 3 و ماوس را روی عبارت «فرانسوی» نگه دارید.
مدل سازی موضوع از طریق LSI
در قسمت قبل روش انجام مدل سازی موضوع از طریق LDA را دیدیم. بیایید ببینیم چگونه میتوانیم مدلسازی موضوع را از طریق نمایهسازی معنایی پنهان (LSI) انجام دهیم.
برای انجام این کار، تنها کاری که باید انجام دهید این است که از آن استفاده کنید LsiModel کلاس بقیه ی process کاملاً مشابه چیزی است که قبلاً با LDA دنبال کردیم.
به اسکریپت زیر نگاه کنید:
from gensim.models import LsiModel
lsi_model = LsiModel(gensim_corpus, num_topics=4, id2word=gensim_dictionary)
topics = lsi_model.print_topics(num_words=10)
for topic in topics:
print(topic)
خروجی به شکل زیر است:
(0, '-0.337*"intelligence" + -0.297*"machine" + -0.250*"artificial" + -0.240*"problem" + -0.208*"system" + -0.200*"learning" + -0.166*"network" + -0.161*"climate" + -0.159*"research" + -0.153*"change"')
(1, '-0.453*"climate" + -0.377*"change" + -0.344*"warming" + -0.326*"global" + -0.196*"emission" + -0.177*"greenhouse" + -0.168*"effect" + 0.162*"intelligence" + -0.158*"temperature" + 0.143*"machine"')
(2, '0.688*"painting" + 0.346*"leonardo" + 0.179*"louvre" + 0.175*"eiffel" + 0.170*"portrait" + 0.147*"french" + 0.127*"museum" + 0.117*"century" + 0.109*"original" + 0.092*"giocondo"')
(3, '-0.656*"eiffel" + 0.259*"painting" + -0.184*"second" + -0.145*"exposition" + -0.145*"structure" + 0.135*"leonardo" + -0.128*"tallest" + -0.116*"engineer" + -0.112*"french" + -0.107*"design"')
نتیجه
مدل سازی موضوع یک کار مهم NLP است. رویکردها و کتابخانههای مختلفی وجود دارد که میتوان از آنها برای مدلسازی موضوع در پایتون استفاده کرد. در این مقاله روش مدلسازی موضوع را از طریق کتابخانه Gensim در پایتون با استفاده از رویکردهای LDA و LSI دیدیم. ما همچنین دیدیم که چگونه نتایج مدل LDA خود را تجسم کنیم.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-22 22:06:04
