از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
این مقاله اولین مقاله از مجموعه است روی کار با PDF در پایتون:
فرمت سند PDF
امروزه، فرمت سند قابل حمل (PDF) به رایج ترین فرمت های داده تعلق دارد. در سال 1990، ساختار یک سند PDF توسط Adobe تعریف شد. ایده پشت فرمت PDF این است که داده ها / اسناد ارسال شده برای هر دو طرفی که در ارتباط هستند دقیقاً یکسان به نظر می رسند. process – خالق، نویسنده یا فرستنده و گیرنده. PDF جانشین آن است پست اسکریپت فرمت، و استاندارد شده به عنوان ISO 32000-2:2017.
پردازش اسناد PDF
برای لینوکس ابزارهای خط فرمان قدرتمندی مانند pdftk و pdfgrep. بهعنوان یک توسعهدهنده، هیجان زیادی برای ساختن نرمافزار شخصی شما وجود دارد که مبتنی بر آن است روی پایتون و از کتابخانه های PDF استفاده می کند که به صورت رایگان در دسترس هستند.
این مقاله آغاز یک سری کوچک است و این کتابخانه های مفید پایتون را پوشش می دهد. در قسمت اول تمرکز خواهیم کرد روی دستکاری فایل های PDF موجود شما یاد خواهید گرفت که چگونه محتوا (هم متن و هم عکس) را بخوانید و استخراج کنید، صفحات تکی را بچرخانید و اسناد را به صفحات جداگانه آن تقسیم کنید. قسمت دوم اضافه کردن واترمارک بر اساس را پوشش خواهد داد روی پوشش ها. بخش سوم منحصراً تمرکز خواهد داشت روی نوشتن/ایجاد PDF، و همچنین شامل حذف و ترکیب مجدد صفحات منفرد در یک سند جدید می شود.
طیف راهحلهای موجود برای ابزارها، ماژولها و کتابخانههای پیدیاف مرتبط با پایتون کمی گیجکننده است و کمی طول میکشد تا بفهمیم چه چیزی چیست و کدام پروژهها به طور مداوم نگهداری میشوند. مستقر روی تحقیقات ما اینها نامزدهایی هستند که به روز هستند:
-
PyPDF2: یک کتابخانه پایتون برای استخراج اطلاعات و محتوای اسناد، تقسیم اسناد page-توسط-page، اسناد را ادغام کنید، صفحات را برش دهید و واترمارک اضافه کنید. PyPDF2 از اسناد رمزگذاری نشده و رمزگذاری شده پشتیبانی می کند.
-
PDFMiner: به طور کامل در پایتون نوشته شده است و برای Python 2.4 به خوبی کار می کند. برای پایتون 3، از بسته کلون شده استفاده کنید PDFMiner.six. هر دو بسته به شما امکان تجزیه، تجزیه و تحلیل و تبدیل اسناد PDF را می دهند. این شامل پشتیبانی از PDF 1.7 و همچنین زبان های CJK (چینی، ژاپنی و کره ای) و انواع فونت (Type1، TrueType، Type3، و CID) می شود.
-
PDFQuery: خود را به عنوان یک “کتابخانه خراش پی دی اف سریع و دوستانه” توصیف می کند که به عنوان یک بسته بندی در اطراف PDFMiner، lxml و گیج کردن. هدف طراحی آن «استخراج مطمئن دادهها از مجموعههای PDF با کمترین کد ممکن است».
-
جدول-py: این یک روکش ساده پایتون است Tabula-java، که می تواند جداول را از PDF بخواند و آنها را به Pandas DataFrames تبدیل کند. همچنین شما را قادر می سازد که یک فایل PDF را به یک فایل CSV/TSV/JSON تبدیل کنید.
-
pdflib برای پایتون: پسوندی از پوپلر کتابخانه ای که پیوندهای پایتون را برای آن ارائه می دهد. این به شما امکان می دهد اسناد PDF را تجزیه، تجزیه و تحلیل و تبدیل کنید. نباید با آن اشتباه گرفته شود آویز تجاری که همین نام را دارد
-
PyFPDF: کتابخانه ای برای تولید اسناد PDF تحت پایتون. منتقل شده از FPDF کتابخانه PHP، یک جایگزین شناخته شده پسوند PDFlib با مثال ها، اسکریپت ها و مشتقات فراوان.
-
جداول PDF: یک سرویس تجاری که استخراج از جداول را به صورت سند PDF ارائه می دهد. یک API ارائه می دهد تا PDFTables را بتوان به عنوان SAAS استفاده کرد.
-
PyX – بسته گرافیکی پایتون: PyX یک بسته پایتون برای ایجاد فایلهای PostScript، PDF و SVG است. این انتزاعی از مدل ترسیم PostScript را با رابط TeX/LaTeX ترکیب می کند. وظایف پیچیده ای مانند ایجاد نمودارهای دوبعدی و سه بعدی با کیفیت آماده انتشار از این موارد اولیه ساخته شده است.
-
ReportLab: یک کتابخانه جاه طلبانه با قدرت صنعتی که عمدتاً متمرکز شده است روی ایجاد دقیق اسناد PDF به صورت آزاد در دسترس است Source نسخه و همچنین یک نسخه تجاری و پیشرفته به نام ReportLab PLUS.
-
PyMuPDF (معروف به “fitz”): اتصالات پایتون برای MuPDF، که یک نمایشگر PDF و XPS سبک وزن است. این کتابخانه میتواند به فایلها در فرمتهای PDF، XPS، OpenXPS، epub، کمیک و کتابهای تخیلی دسترسی داشته باشد و به خاطر عملکرد عالی و کیفیت رندر بالا شهرت دارد.
-
pdfrw: یک تجزیه کننده PDF خالص مبتنی بر پایتون برای خواندن و نوشتن PDF. فرمت های برداری را بدون شطرنجی به طور صادقانه بازتولید می کند. در ارتباط با ReportLab، به استفاده مجدد از بخش هایی از PDF های موجود در PDF های جدید ایجاد شده با ReportLab کمک می کند.
| کتابخانه | استفاده برای |
|---|---|
| PyPDF2 | خواندن |
| PyMuPDF | خواندن |
| pdflib | خواندن |
| جداول PDF | خواندن |
| جدول-py | خواندن |
| PDFMiner.six | خواندن |
| PDFQuery | خواندن |
| pdfrw | خواندن، نوشتن / ایجاد |
| Reportlab | نوشتن / ایجاد |
| PyX | نوشتن / ایجاد |
| PyFPDF | نوشتن / ایجاد |
در زیر به تمرکز خواهیم پرداخت روی PyPDF2 و PyMuPDF و روش استخراج متن و تصاویر را به ساده ترین شکل ممکن توضیح دهید. به منظور درک استفاده از PyPDF2، ترکیبی از اسناد رسمی و نمونه های زیادی که از منابع دیگر در دسترس هستند، کمک می کند. در مقابل، اسناد رسمی PyMuPDF با استفاده از کتابخانه بسیار واضح تر و به طور قابل توجهی سریعتر است.
PyPDF2 را می توان به عنوان یک بسته نرم افزاری معمولی یا با استفاده از آن نصب کرد pip3 (برای Python3). تست های اینجا بر اساس روی بسته برای دبیان آینده GNU/لینوکس نسخه 10 “Buster”. نام بسته دبیان است python3-pypdf2.
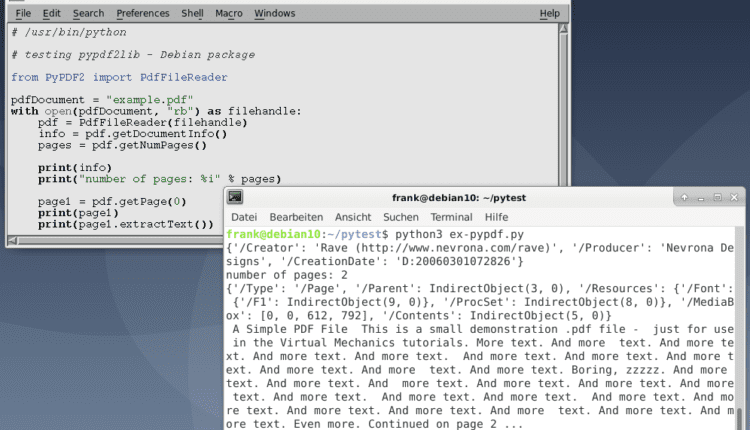
لیست 1 وارد می کند PdfFileReader کلاس، اول سپس با استفاده از این کلاس، سند را باز می کند و اطلاعات سند را با استفاده از آن استخراج می کند getDocumentInfo() روش، تعداد صفحات استفاده شده getDocumentInfo()، و محتوای اول page.
لطفاً توجه داشته باشید که PyPDF2 شمارش صفحات را با 0 شروع می کند و به همین دلیل است که تماس گرفته می شود pdf.getPage(0) اولی را بازیابی می کند page از سند در نهایت اطلاعات استخراج شده در آن چاپ می شود stdout.
فهرست 1: استخراج اطلاعات و محتوای سند.
from PyPDF2 import PdfFileReader
pdf_document = "example.pdf"
with open(pdf_document, "rb") as filehandle:
pdf = PdfFileReader(filehandle)
info = pdf.getDocumentInfo()
pages = pdf.getNumPages()
print (info)
print ("number of pages: %i" % pages)
page1 = pdf.getPage(0)
print(page1)
print(page1.extractText())

شکل 1: متن استخراج شده از یک فایل PDF با استفاده از PyPDF2
همانطور که در نشان داده شده است شکل 1 در بالا، متن استخراج شده چاپ شده است روی یک مبنای مستمر هیچ پاراگراف یا جداسازی جمله ای وجود ندارد. همانطور که در مستندات PyPDF2 بیان شد، تمام داده های متنی به ترتیبی که در جریان محتوایی ارائه شده اند، بازگردانده می شوند. page، و با تکیه روی ممکن است به برخی شگفتی ها منجر شود. این عمدتا بستگی دارد روی ساختار داخلی سند PDF و روش تولید جریان دستورالعمل های PDF توسط PDF writer process.
PyMuPDF از وب سایت PyPi در دسترس است و شما بسته را با دستور زیر در a نصب می کنید terminal:
$ pip3 install PyMuPDF
نمایش اطلاعات سند، چاپ تعداد صفحات و استخراج متن یک سند PDF به روشی مشابه PyPDF2 انجام می شود (نگاه کنید به لیست 2). ماژولی که قرار است وارد شود نامگذاری شده است fitz، و به نام قبلی PyMuPDF برمی گردد.
فهرست 2: استخراج محتوا از یک سند PDF با استفاده از PyMuPDF.
import fitz
pdf_document = "example.pdf"
doc = fitz.open(pdf_document):
print ("number of pages: %i" % doc.pageCount)
print(doc.metadata)
page1 = doc.loadPage(0)
page1text = page1.getText("text")
print(page1text)
نکته خوب در مورد PyMuPDF این است که ساختار سند اصلی را دست نخورده نگه میدارد – کل پاراگرافها با شکست خط همانطور که در سند PDF هستند حفظ میشوند (نگاه کنید به شکل 2).

شکل 2: داده های متنی استخراج شده
PyMuPDF استخراج تصاویر از اسناد PDF را با استفاده از این روش ساده می کند getPageImageList(). لیست 3 بر اساس روی نمونه ای از ویکی PyMuPDF page، و تمام تصاویر را از PDF به عنوان فایل PNG استخراج و ذخیره می کند روی آ page-توسط-page اساس اگر تصویری دارای فضای رنگی CMYK باشد، ابتدا به RGB تبدیل می شود.
فهرست 3: استخراج تصاویر.
import fitz
pdf_document = fitz.open("file.pdf")
for current_page in range(len(pdf_document)):
for image in pdf_document.getPageImageList(current_page):
xref = image(0)
pix = fitz.Pixmap(pdf_document, xref)
if pix.n < 5:
pix.writePNG("page%s-%s.png" % (current_page, xref))
else:
pix1 = fitz.Pixmap(fitz.csRGB, pix)
pix1.writePNG("page%s-%s.png" % (current_page, xref))
pix1 = None
pix = None
اجرای این اسکریپت پایتون روی یک 400 page PDF، 117 تصویر را در کمتر از 3 ثانیه استخراج کرد که بسیار شگفت انگیز است. تصاویر جداگانه در فرمت PNG ذخیره می شوند. برای حفظ فرمت و اندازه تصویر اصلی، به جای تبدیل به PNG، نگاهی به نسخه های توسعه یافته اسکریپت ها در ویکی PyMuPDF.

شکل 3: تصاویر استخراج شده
تقسیم PDF به صفحات با PyPDF2
برای این مثال، هر دو PdfFileReader و PdfFileWriter کلاس ها ابتدا باید وارد شوند. سپس فایل PDF را باز می کنیم، یک شی خواننده ایجاد می کنیم و با استفاده از شی Reader روی تمام صفحات حلقه می زنیم. getNumPages روش.
داخل از for حلقه، ما یک نمونه جدید از PdfFileWriter، که هنوز هیچ صفحه ای ندارد. سپس جریان را اضافه می کنیم page به شی نویسنده ما با استفاده از pdfWriter.addPage() روش. این روش الف را می پذیرد page شی، که ما با استفاده از PdfFileReader.getPage() روش.
مرحله بعدی ایجاد یک نام فایل منحصر به فرد است که با استفاده از نام اصلی فایل به اضافه کلمه “” این کار را انجام می دهیم.page”، به علاوه page عدد. 1 را به جریان اضافه می کنیم page عدد زیرا PyPDF2 عدد را می شمارد page اعدادی که از صفر شروع می شوند
در نهایت، نام فایل جدید را در حالت «نوشتن باینری» باز میکنیم (حالت wb) و استفاده کنید write() روش از pdfWriter کلاس برای ذخیره موارد استخراج شده page به دیسک
فهرست 4: تقسیم یک PDF به صفحات تک.
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "example.pdf"
pdf = PdfFileReader(pdf_document)
for page in range(pdf.getNumPages()):
pdf_writer = PdfFileWriter
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
outputFilename = "example-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename)

شکل 4: تقسیم یک PDF
همه صفحات حاوی متن را پیدا کنید
این مورد کاملاً کاربردی است و مشابه آن عمل می کند pdfgrep. با استفاده از PyMuPDF، اسکریپت تمام موارد را برمی گرداند page اعدادی که شامل رشته جستجوی داده شده هستند. صفحات یکی پس از دیگری و با کمک searchFor() روش تمام رخدادهای رشته جستجو شناسایی می شوند. در صورت تطابق یک پیام مطابق چاپ می شود روی stdout.
فهرست 5: یک متن داده شده را جستجو کنید.
import fitz
filename = "example.pdf"
search_term = "invoice"
pdf_document = fitz.open(filename):
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s found روی page %i" % (search_term, current_page))
شکل 5 در زیر نتیجه جستجوی عبارت “Debian” را نشان می دهد GNU/Linux” در 400-page کتاب.

شکل 5: جستجوی یک سند PDF
نتیجه
روش های نشان داده شده در اینجا بسیار قدرتمند هستند. با تعداد نسبتاً کمی از خطوط کد، نتیجه به راحتی بدست می آید. موارد استفاده بیشتر در قسمت دوم (به زودی!) مورد بررسی قرار می گیرند که شامل افزودن واترمارک به PDF می شود.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-23 13:42:04
