از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
در مقاله قبلی خود توضیح دادم که چگونه کتابخانه Seaborn می تواند برای تجسم داده های پیشرفته در پایتون استفاده شود. Seaborn یک کتابخانه عالی است و من همیشه ترجیح می دهم با آن کار کنم، با این حال، کمی کتابخانه پیشرفته است و برای عادت کردن به کمی زمان و تمرین نیاز دارد.
در این مقاله خواهیم دید که چگونه می توان از پانداها که یکی دیگر از کتابخانه های بسیار مفید پایتون است برای تجسم داده ها در پایتون استفاده کرد. Pandas در درجه اول برای وارد کردن و مدیریت مجموعه داده ها در قالب های مختلف استفاده می شود که در مقاله آموزش مبتدی توضیح داده شده است. روی کتابخانه پایتون پانداها قابلیت های تجسم داده پانداها کمتر شناخته شده است. در این مقاله تمرکز خواهید کرد روی قابلیت تجسم داده های پانداها
لازم به ذکر است که مانند Seaborn، قابلیتهای تجسم دادههای پاندا نیز مبتنی است روی را کتابخانه Matplotlib. اما با پانداها میتوانید مستقیماً انواع مختلف تجسمها را مستقیماً از چارچوب دادههای پاندا ترسیم کنید که در این مقاله خواهیم دید.
توطئه های اساسی
در این قسمت خواهیم دید که چگونه می توان از دیتافریم های پاندا برای رسم نمودارهای ساده مانند هیستوگرام، نمودار شمارش، نمودار پراکندگی و غیره استفاده کرد.
مجموعه داده
مجموعه داده ای که قرار است از آن برای رسم این نمودارها استفاده کنیم مجموعه داده معروف تایتانیک است. مجموعه داده را می توان از دانلود کرد کاگل. در این مقاله، ما از آن استفاده خواهیم کرد train.csv فایل.
قبل از ما import مجموعه داده را در برنامه ما نیاز داریم import کتابخانه های مورد نیاز اسکریپت زیر را اجرا کنید
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
اسکریپت زیر مجموعه داده را وارد می کند.
titanic_data = pd.read_csv(r"E:\Datasets\train.csv")
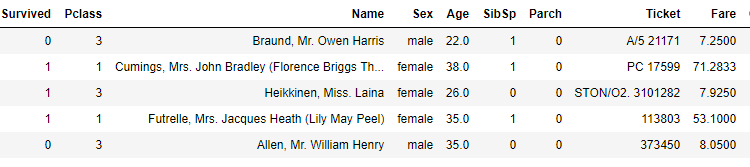
بیایید ببینیم مجموعه داده ما در واقع چگونه به نظر می رسد. اسکریپت زیر را اجرا کنید:
titanic_data.head()
خروجی به شکل زیر است:

می بینید که مجموعه داده حاوی اطلاعاتی در مورد مسافران کشتی تایتانیک ناگوار است که در اقیانوس اطلس شمالی در سال 1912 غرق شد. مجموعه داده شامل اطلاعاتی مانند نام، سن، کلاس مسافر، زنده ماندن یا نبودن مسافر و غیره است.
بیایید با استفاده از این اطلاعات چند نمودار اساسی ترسیم کنیم.
هیستوگرام
برای رسم هیستوگرام برای هر ستون، باید نام ستون و سپس روش را مشخص کنید hist()روش نشان داده شده در زیر:
titanic_data('Age').hist()
می توانید ببینید چقدر آسان است که یک هیستوگرام برای ستون سن با استفاده از چارچوب داده پاندا رسم کنید. خروجی اسکریپت بالا به شکل زیر است:

می توانید پارامترهای مبتنی بر Matplotlib را به hist() روش از آنجایی که پانداها در پشت صحنه از کتابخانه Matplotlib استفاده می کنند. بنابراین، برای مثال، میتوانید تعداد binها را برای هیستوگرام خود افزایش دهید bin ویژگی، به شرح زیر:
titanic_data('Age').hist(bins=20)
در اسکریپت بالا، تعداد bin ها را برای هیستوگرام خود 20 قرار دادیم. خروجی به صورت زیر است:

میتوانید با وارد کردن کتابخانه Seaborn و تعیین مقدار برای آن، استایل طرحها را بهبود ببخشید set_style صفت. برای مثال، اجازه دهید سبک شبکه را روی خاکستری تیره تنظیم کنیم. اسکریپت زیر را اجرا کنید:
import seaborn as sns
sns.set_style('darkgrid')
اکنون دوباره هیستوگرام را با استفاده از اسکریپت زیر رسم کنید:
titanic_data('Age').hist(bins=20)
در خروجی، شبکه های خاکستری تیره را در پس زمینه طرح ما خواهید دید:

دو روش وجود دارد که می توانید از dataframe برای رسم نمودارها استفاده کنید. یکی از راه ها این است که مقدار را برای kind پارامتر از plot مطابق شکل زیر عمل کنید:
titanic_data('Age').plot(kind='hist', bins=20)
خروجی به شکل زیر است:

راه دیگر فراخوانی مستقیم نام متد برای نمودار با استفاده از plot تابع بدون ارسال نام تابع به kind صفت. ما از دومی استفاده خواهیم کرد (نام متد را برای نمودار با استفاده از plot تابع) روش از اینجا روی.
طرح های خطی
برای رسم نمودارهای خط با دیتافریم پاندا، باید با آن تماس بگیرید line() روش با استفاده از plot تابع و مقدار را برای شاخص x و محور y، مانند شکل زیر ارسال کنید:
titanic_data.plot.line(x='Age', y='Fare', figsize=(8,6))
اسکریپت بالا یک طرح خطی را ترسیم می کند که در آن محور x شامل سن مسافران و محور y شامل کرایه های پرداخت شده توسط مسافران است. می بینید که ما می توانیم از آن استفاده کنیم figsize ویژگی برای تغییر اندازه طرح. خروجی به شکل زیر است:

پلات های پراکنده
برای رسم نمودارهای خط با دیتافریم پاندا، باید با آن تماس بگیرید scatter() روش با استفاده از plot تابع و مقدار را برای شاخص x و محور y مطابق شکل زیر ارسال کنید:
titanic_data.plot.scatter(x='Age', y='Fare', figsize=(8,6))
خروجی اسکریپت بالا به شکل زیر است:

طرح جعبه
از دیتافریم های پاندا نیز می توان برای رسم نمودار جعبه استفاده کرد. تنها کاری که باید انجام دهید این است که با این شماره تماس بگیرید box() روش با استفاده از plot عملکرد چارچوب داده پاندا:
titanic_data.plot.box(figsize=(10,8))
در خروجی، نمودارهای جعبه ای برای تمام ستون های عددی در مجموعه داده تایتانیک را خواهید دید:

قطعه های شش ضلعی
نمودارهای شش ضلعی شش ضلعی ها را برای نقاط داده ای متقاطع رسم می کنند روی محور x و y هرچه نقاط بیشتری قطع شوند، شش ضلعی تیره تر است. برای ترسیم نمودارهای شش ضلعی با دیتافریم پاندا، باید با آن تماس بگیرید hexbin() روش با استفاده از plot تابع و مقدار را برای شاخص x و محور y مطابق شکل زیر ارسال کنید:
titanic_data.plot.hexbin(x='Age', y='Fare', gridsize=30, figsize=(8,6))
در خروجی نمودار شش ضلعی را با سن مشاهده خواهید کرد روی محور x و کرایه روی محور y

نمودارهای چگالی هسته
مانند Seaborn و Matplotlib، ما همچنین می توانیم نمودارهای چگالی هسته را با کتابخانه پاندا رسم کنیم. برای رسم نمودارهای چگالی هسته با دیتافریم پاندا، باید آن را فراخوانی کنید kde() روش با استفاده از plot تابع:
titanic_data('Age').plot.kde()
خروجی اسکریپت بالا به شکل زیر است:

در این بخش دیدیم که چگونه می توان از کتابخانه Pandas برای ترسیم برخی از ابتدایی ترین نمودارها استفاده کرد. با این حال، استفاده از کتابخانه پانداها برای تجسم داده ها به چنین نمودارهای اساسی محدود نمی شود. در عوض، پانداها همچنین می توانند برای تجسم داده های سری زمانی استفاده شوند که در بخش بعدی خواهیم دید.
پانداها برای تجسم سری های زمانی
دادههای سری زمانی نوعی داده است که در آن ویژگیها یا ویژگیها به شاخص زمانی وابسته هستند که یکی از ویژگیهای مجموعه داده نیز میباشد. برخی از رایجترین نمونههای دادههای سری زمانی شامل تعداد اقلام فروخته شده در ساعت، دمای روزانه و قیمت روزانه سهام است. در تمام این مثال ها، داده ها وابسته هستند روی مقداری واحد زمان و با توجه به آن واحد زمانی متفاوت است. واحد زمان می تواند ساعت، روز، هفته، سال و غیره باشد روی و غیره
از کتابخانه پانداها می توان برای تجسم روز سری زمانی استفاده کرد. کتابخانه Pandas دارای توابع داخلی است که می توان از آنها برای انجام کارهای مختلف استفاده کرد روی داده های سری زمانی مانند جابجایی زمانی و نمونه برداری زمانی. در این قسمت با کمک مثال هایی روش استفاده از کتابخانه پانداها برای تجسم سری های زمانی را خواهیم دید. اما ابتدا به داده های سری زمانی نیاز داریم.
مجموعه داده
همانطور که قبلاً گفته شد، یکی از نمونه های داده های سری زمانی، قیمت سهام است که با توجه به زمان متفاوت است. در این بخش، از قیمت سهام AAPL برای 5 سال (از 12-11-2013 تا 12-11-2018) برای تجسم داده های سری زمانی استفاده خواهیم کرد. مجموعه داده را می توان از این لینک یاهو فاینانس. برای اطلاعات دیگر شرکت، فقط به وب سایت آنها بروید، نام شرکت و دوره زمانی که می خواهید داده های شما برای آن دانلود شود را تایپ کنید. مجموعه داده در قالب CSV دانلود خواهد شد.
اجازه دهید import کتابخانههایی که میخواهیم برای تجسم دادههای سری زمانی در پانداها استفاده کنیم. اسکریپت زیر را اجرا کنید:
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
جنب import مجموعه داده، ما استفاده خواهیم کرد read_csv() روش کتابخانه پانداها به شرح زیر است:
apple_data = pd.read_csv(r'F:/AAPL.csv')
برای اینکه ببینیم مجموعه داده ما چگونه به نظر می رسد، می توانیم از آن استفاده کنیم head() تابع. اسکریپت زیر را اجرا کنید:
apple_data.head()
در خروجی، پنج ردیف اول مجموعه داده را خواهید دید.

می بینید که مجموعه داده شامل تاریخ، قیمت باز و بسته شدن سهام در روز، بالاترین و کمترین قیمت سهام در روز، قیمت بسته تعدیل شده و حجم سهام است. می بینید که تمام ستون ها وابسته هستند روی تاریخ تغییر در ستون تاریخ باعث تغییر در تمام ستون های دیگر می شود. بنابراین، Date ستون شاخص در این مورد است. با این حال، در مجموعه داده ما، به طور پیش فرض تاریخ به عنوان یک رشته در نظر گرفته می شود. ابتدا باید نوع ستون Date را از رشته به DateTime تغییر دهیم و سپس باید ستون Date را به عنوان ستون شاخص تنظیم کنیم.
برای تغییر نوع ستون DateTime به رشته، اسکریپت زیر را اجرا کنید.
apple_data('Date') = apple_data('Date').apply(pd.to_datetime)
در اسکریپت بالا ما از to_datetime متد به ستون Date مجموعه داده ما به منظور تغییر نوع آن.
در مرحله بعد، باید ستون Date را به عنوان ستون شاخص تنظیم کنیم. اسکریپت زیر این کار را انجام می دهد:
apple_data.set_index('Date', inplace=True)
در اسکریپت بالا از set_index متد Pandas dataframe و ستون ‘Date’ را به عنوان پارامتر ارسال کنید. صفت inplace=True به این معنی است که تبدیل انجام می شود و نیازی نیست نتیجه را در متغیر دیگری ذخیره کنید.
حالا وقته print پنج ردیف اول مجموعه داده ما دوباره با استفاده از head() تابع:
apple_data.head()
خروجی اسکریپت بالا به شکل زیر است:

از خروجی، می بینید که اکنون مقادیر در ستون Date پررنگ هستند، که نشان دهنده این واقعیت است که ستون Date اکنون به عنوان ستون شاخص استفاده می شود.
قبل از اینکه حرکت کنیم روی به بخش تغییر زمان، اجازه دهید فقط قیمت پایانی سهام اپل را ترسیم کنیم. اسکریپت زیر را اجرا کنید:
plt.rcParams('figure.figsize') = (8,6)
apple_data("Close").plot(grid=True)
توجه کنید که در اسکریپت بالا ما به سادگی آن را می نامیم plot روش روی ستون “بستن”. ما هیچ اطلاعاتی در مورد تاریخ مشخص نکردیم، اما از آنجایی که ستون Date یک ستون شاخص است، محور x حاوی مقادیر ستون Date است در حالی که محور y قیمت سهام بسته شدن را نشان می دهد. خروجی اسکریپت بالا به شکل زیر است:

پانداها می توانند کارهای تجسمی مختلفی را انجام دهند روی دادههای سری زمانی مانند جابهجایی زمانی، نمونهبرداری زمانی، گسترش نورد، پیشبینی سریهای زمانی. در این مقاله شاهد دو کاربرد تجسم سری زمانی پانداها خواهیم بود: Time Shifting و Time Sampling.
تغییر زمان
جابجایی زمان به حرکت داده ها در تعداد معینی گام به جلو یا عقب اشاره دارد. جابجایی سری های زمانی یکی از مهمترین وظایف در تحلیل سری های زمانی است.
ما سر مجموعه داده را قبلا رسم کردیم، اکنون ابتدا دنباله مجموعه داده خود را رسم می کنیم. بعداً از این فریمهای داده سر و دم برای مشاهده تأثیرات تغییر زمان استفاده خواهیم کرد.
برای رسم دنباله مجموعه داده، می توانیم از tail() عملکرد به شرح زیر است:
apple_data.tail()
در خروجی، پنج ردیف آخر مجموعه داده را مطابق شکل زیر خواهید دید:

بیایید ابتدا داده ها را به جلو ببریم تا ببینیم که تغییر زمان چگونه در جهت مثبت عمل می کند. برای جابهجایی دادهها در تعداد معینی از گامهای زمانی به جلو، فقط باید با آن تماس بگیرید shift() روش روی مجموعه داده و آن را یک عدد صحیح مثبت ارسال کنید. به عنوان مثال، اسکریپت زیر داده ها را دو مرحله به جلو منتقل می کند و سپس سر داده ها را چاپ می کند:
apple_data.shift(2).head()
در خروجی مشاهده می کنید که هیچ داده ای برای دو ردیف اول هد نمایش داده نمی شود زیرا داده های این ردیف ها دو مرحله به جلو منتقل می شوند. در خروجی مشاهده می کنید که داده هایی که قبلاً متعلق به شاخص اول یعنی 2013-12-10 بوده است، پس از دو قدم جلو افتادن، متعلق به شاخص سوم یعنی 2013-12-2012 مطابق شکل زیر است:

از طرف دیگر، برای جابجایی داده ها به عقب، می توانید دوباره از shift() تابع اما باید مقدار منفی را مشخص کنید. به عنوان مثال، برای جابجایی داده ها 2 مرحله به عقب می توانید از اسکریپت زیر استفاده کنید:
apple_data.shift(-2).tail()
در اسکریپت بالا داده ها 2 پله به عقب جابه جا شده و سپس دم داده ها نمایش داده می شود. در خروجی مشاهده خواهید کرد که دو سطر آخر هیچ رکوردی ندارند زیرا داده ها مانند شکل زیر دو مرحله به عقب منتقل می شوند:

نمونه برداری زمانی
نمونهگیری زمانی به گروهبندی ویژگیهای داده یا ویژگیهای مبتنی بر آن اشاره دارد روی مقدار تجمیع شده ستون شاخص برای مثال، اگر میخواهید حداکثر قیمت سهام افتتاحیه در سال را برای تمام سالهای موجود در مجموعه داده ببینید، میتوانید از نمونهگیری زمانی استفاده کنید.
اجرای نمونه برداری زمانی با پانداها بسیار ساده است. باید با resample() روش با استفاده از چارچوب داده Pandas. شما همچنین باید مقدار را برای rule صفت. مقدار اساساً زمان آفست است که محدوده زمانی را که میخواهیم دادههای خود را گروهبندی کنیم را مشخص میکند.
در نهایت، باید تابع تجمع را فراخوانی کنید mean، max، minو غیره. اسکریپت زیر حداکثر مقدار را برای تمام ویژگی ها برای هر ماه در مجموعه داده نمایش می دهد:
apple_data.resample(rule='M').max()
خروجی اسکریپت بالا به شکل زیر است:

لیست دقیق مقادیر افست برای rule ویژگی به شرح زیر است:
B business day frequency
C custom business day frequency (experimental)
D calendar day frequency
W weekly frequency
M month end frequency
SM semi-month end frequency (15th and end of month)
BM business month end frequency
CBM custom business month end frequency
MS month start frequency
SMS semi-month start frequency (1st and 15th)
BMS business month start frequency
CBMS custom business month start frequency
Q quarter end frequency
BQ business quarter end frequency
QS quarter start frequency
BQS business quarter start frequency
A year end frequency
BA business year end frequency
AS year start frequency
BAS business year start frequency
BH business hour frequency
H hourly frequency
T minutely frequency
S secondly frequency
L milliseconds
U microseconds
N nanoseconds
لیست فوق از سایت گرفته شده است پانداهای رسمی Documentation.
حالا بیایید سعی کنیم print میانگین سه ماهه (هر سه ماه) مقادیر برای مجموعه داده. شما می توانید از لیست افست ببینید که Q برای دفعات سه ماهه استفاده می شود. اسکریپت زیر را اجرا کنید:
apple_data.resample(rule='Q').mean()
خروجی اسکریپت بالا به شکل زیر است:

علاوه بر یافتن مقادیر تجمیع شده برای تمام ستون های مجموعه داده. شما همچنین می توانید داده ها را برای یک ستون خاص دوباره نمونه برداری کنید. بیایید نمودار نواری را رسم کنیم که میانگین سالانه ویژگی “بستن” مجموعه داده ما را نشان می دهد. اسکریپت زیر را اجرا کنید:
plt.rcParams('figure.figsize') = (7, 5)
apple_data('Close').resample('A').mean().plot(kind='bar')
شما می توانید ببینید که برای رسم نمودار میله ای، فقط باید آن را فراخوانی کنید plot بعد از تابع مجموع عمل کنید و نوع نموداری را که می خواهید رسم کنید به آن منتقل کنید. خروجی اسکریپت بالا به شکل زیر است:

به طور مشابه، برای رسم نمودار خطی که حداکثر ارزش ماهانه قیمت سهام را برای ویژگی “Close” نمایش می دهد، می توانید از اسکریپت زیر استفاده کنید:
plt.rcParams('figure.figsize') = (7, 5)
apple_data('Close').resample('M').max().plot(kind='line')
خروجی اسکریپت بالا به شکل زیر است:

نتیجه
Pandas یکی از مفیدترین کتابخانه های پایتون برای علم داده است. معمولاً از Pandas برای وارد کردن، دستکاری و تمیز کردن مجموعه داده استفاده می شود. با این حال، همانطور که در این مقاله نشان دادیم، می توان از پانداها برای تجسم داده ها نیز استفاده کرد.
در این مقاله با کمک مثال های مختلف دیدیم که چگونه می توان از پانداها برای ترسیم طرح های اساسی استفاده کرد. ما همچنین بررسی کردیم که چگونه می توان از عملکردهای پاندا برای تجسم داده های سری زمانی استفاده کرد. به عنوان یک قاعده کلی، اگر واقعاً مجبور هستید یک نوار ساده، خط یا تعداد نمودارها را ترسیم کنید، باید از پانداها استفاده کنید.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-25 17:27:03
