از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
در مقاله قبلی، روش پایتون را بررسی کردیم کتابخانه Matplotlib می تواند برای تجسم داده ها استفاده شود. در این مقاله به بررسی خواهیم پرداخت متولد دریا که یکی دیگر از کتابخانه های بسیار مفید برای تجسم داده ها در پایتون است. کتابخانه Seaborn ساخته شده است روی بالای Matplotlib است و بسیاری از قابلیت های تجسم داده های پیشرفته را ارائه می دهد.
اگرچه می توان از کتابخانه Seaborn برای ترسیم نمودارهای مختلفی مانند نمودارهای ماتریسی، نمودارهای شبکه ای، نمودارهای رگرسیون و غیره استفاده کرد، در این مقاله خواهیم دید که چگونه می توان از کتابخانه Seaborn برای ترسیم نمودارهای توزیعی و طبقه بندی استفاده کرد. در قسمت دوم مجموعه، روش رسم نمودارهای رگرسیون، نمودارهای ماتریسی و نمودارهای شبکه ای را خواهیم دید.
دانلود کتابخانه Seaborn
را seaborn کتابخانه را می توان به چند روش دانلود کرد. اگر استفاده می کنید pip نصب کننده کتابخانه های پایتون، می توانید دستور زیر را برای دانلود کتابخانه اجرا کنید:
pip install seaborn
از طرف دیگر، اگر از توزیع Anaconda پایتون استفاده می کنید، می توانید از دستور زیر برای دانلود استفاده کنید. seaborn کتابخانه:
conda install seaborn
مجموعه داده
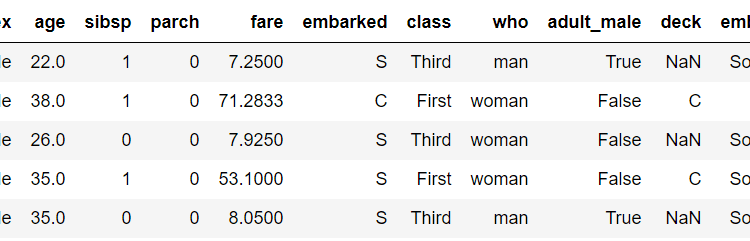
مجموعه داده ای که قرار است از آن برای ترسیم نمودارهای خود استفاده کنیم، مجموعه داده تایتانیک خواهد بود که به طور پیش فرض با کتابخانه Seaborn دانلود می شود. تنها کاری که باید انجام دهید استفاده از load_dataset تابع و آن را به نام مجموعه داده ارسال کنید.
بیایید ببینیم مجموعه داده تایتانیک چگونه به نظر می رسد. اسکریپت زیر را اجرا کنید:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
dataset = sns.load_dataset('titanic')
dataset.head()
اسکریپت بالا مجموعه داده تایتانیک را بارگیری می کند و پنج ردیف اول مجموعه داده را با استفاده از تابع head نمایش می دهد. خروجی به شکل زیر است:

مجموعه داده شامل 891 ردیف و 15 ستون و حاوی اطلاعاتی در مورد مسافرانی است که سوار کشتی تایتانیک تایتانیک شده اند. وظیفه اصلی این است که پیش بینی کنیم آیا مسافر بسته به ویژگی های مختلف مانند سن، بلیط، کابینی که سوار شده است، کلاس بلیط و غیره زنده مانده است یا نه. داده.
قطعه های توزیعی
نمودارهای توزیعی همانطور که از نام آن پیداست انواع نمودارهایی هستند که توزیع آماری داده ها را نشان می دهند. در این بخش تعدادی از پرکاربردترین قطعات توزیع در Seaborn را مشاهده خواهیم کرد.
توطئه دور
را distplot() توزیع هیستوگرام داده ها را برای یک ستون نشان می دهد. نام ستون به عنوان پارامتر به distplot() تابع. بیایید ببینیم قیمت بلیط برای هر مسافر چگونه توزیع می شود. اسکریپت زیر را اجرا کنید:
sns.distplot(dataset('fare'))
خروجی:

می بینید که اکثر بلیط ها بین 0-50 دلار حل شده اند. خطی که می بینید نشان دهنده آن است تخمین چگالی هسته. شما می توانید این خط را با عبور حذف کنید False به عنوان پارامتر برای kde ویژگی مطابق شکل زیر:
sns.distplot(dataset('fare'), kde=False)
خروجی:

اکنون می توانید ببینید که هیچ خطی برای تخمین چگالی هسته وجود ندارد روی طرح.
شما همچنین می توانید مقدار را برای bins پارامتر برای دیدن جزئیات بیشتر یا کمتر در نمودار. به اسکریپت زیر نگاهی بیندازید:
sns.distplot(dataset('fare'), kde=False, bins=10)
در اینجا ما تعداد bin ها را 10 قرار می دهیم. در خروجی، داده هایی را مشاهده می کنید که در 10 bin مانند شکل زیر توزیع شده اند:
خروجی:

به وضوح می بینید که برای بیش از 700 مسافر، قیمت بلیط بین 0 تا 50 است.
طرح مشترک
را jointplot()برای نمایش توزیع متقابل هر ستون استفاده می شود. شما باید سه پارامتر را به jointplot. اولین پارامتر نام ستونی است که می خواهید توزیع داده ها را برای آن نمایش دهید روی محور x پارامتر دوم نام ستونی است که می خواهید توزیع داده ها را برای آن نمایش دهید روی محور y در نهایت، پارامتر سوم نام قاب داده است.
بیایید یک طرح مشترک از age و fare ستون ها را بررسی کنیم تا ببینیم آیا می توانیم رابطه ای بین این دو پیدا کنیم.
sns.jointplot(x='age', y='fare', data=dataset)
خروجی:

از خروجی می بینید که یک طرح مشترک دارای سه قسمت است. نمودار توزیع در بالای ستون روی محور x، نمودار توزیع روی سمت راست برای ستون روی محور y و نمودار پراکندگی بین آنها که توزیع متقابل داده ها را برای هر دو ستون نشان می دهد. می بینید که هیچ ارتباطی بین قیمت ها و کرایه ها مشاهده نمی شود.
شما می توانید نوع نمودار مشترک را با ارسال یک مقدار برای the تغییر دهید kind پارامتر. به عنوان مثال، اگر به جای نمودار پراکندگی، بخواهید توزیع داده ها را به صورت نمودار شش ضلعی نمایش دهید، می توانید مقدار را ارسال کنید. hex برای kind پارامتر. به اسکریپت زیر نگاه کنید:
sns.jointplot(x='age', y='fare', data=dataset, kind='hex')
خروجی:

در نمودار شش ضلعی، شش ضلعی با بیشترین تعداد نقطه رنگ تیره تر می شود. بنابراین اگر به طرح بالا نگاه کنید، می بینید که بیشتر مسافران بین 20 تا 30 سال سن دارند و بیشتر آنها بین 10 تا 50 برای بلیط پرداخت کرده اند.
طرح جفت
را paitplot() نوعی نمودار توزیع است که اساساً یک نمودار مشترک برای تمام ترکیب ممکن از ستون های عددی و بولی در مجموعه داده شما ترسیم می کند. شما فقط باید نام مجموعه داده خود را به عنوان پارامتر به آن ارسال کنید pairplot() مطابق شکل زیر عمل کنید:
sns.pairplot(dataset)
تصویری از بخشی از خروجی در زیر نشان داده شده است:

توجه داشته باشید: قبل از اجرای اسکریپت بالا، با استفاده از دستور زیر، تمام مقادیر null را از مجموعه داده حذف کنید:
dataset = dataset.dropna()
از خروجی نمودار جفت می توانید نمودارهای مشترک برای تمام ستون های عددی و بولی در مجموعه داده تایتانیک را مشاهده کنید.
برای افزودن اطلاعات از ستون طبقهبندی به نمودار جفت، میتوانید نام ستون طبقهبندی را به hue پارامتر. به عنوان مثال، اگر بخواهیم اطلاعات جنسیت را ترسیم کنیم روی در طرح جفت، می توانیم اسکریپت زیر را اجرا کنیم:
sns.pairplot(dataset, hue='sex')
خروجی:

در خروجی می توانید اطلاعات مربوط به نرها را با رنگ نارنجی و اطلاعات مربوط به ماده را با رنگ آبی مشاهده کنید (همانطور که در افسانه نشان داده شده است). از طرح مشترک روی بالا سمت چپ، به وضوح می توانید ببینید که در میان مسافران زنده مانده، اکثریت زن بودند.
طرح فرش
را rugplot() برای ترسیم نوارهای کوچک در امتداد محور x برای هر نقطه از مجموعه داده استفاده می شود. برای ترسیم طرح فرش، باید نام ستون را بنویسید. بیایید یک قطعه فرش برای کرایه طرح کنیم.
sns.rugplot(dataset('fare'))
خروجی:

از خروجی، می توانید آن را همانطور که در مورد بود مشاهده کنید distplot()، بیشتر نمونه های کرایه ها دارای مقادیری بین 0 تا 100 هستند.
اینها برخی از رایج ترین نمودارهای توزیعی هستند که توسط کتابخانه Seaborn Python ارائه شده است. بیایید برخی از طرح های طبقه بندی شده در کتابخانه Seaborn را ببینیم.
قطعه های طبقه بندی شده
نمودارهای طبقه بندی، همانطور که از نام پیداست معمولاً برای رسم داده های طبقه بندی استفاده می شوند. نمودارهای طبقه بندی مقادیر موجود در ستون طبقه بندی را در مقابل یک ستون دسته بندی دیگر یا یک ستون عددی رسم می کنند. بیایید برخی از متداول ترین داده های طبقه بندی شده را ببینیم.
طرح نوار
را barplot() برای نمایش مقدار میانگین برای هر مقدار در یک ستون طبقه بندی شده، در برابر یک ستون عددی استفاده می شود. پارامتر اول ستون طبقه بندی، پارامتر دوم ستون عددی و پارامتر سوم مجموعه داده است. به عنوان مثال، اگر می خواهید میانگین سن مسافران زن و مرد را بدانید، می توانید از نمودار نوار به صورت زیر استفاده کنید.
sns.barplot(x='sex', y='age', data=dataset)
خروجی:

از خروجی، به وضوح می توانید ببینید که میانگین سنی مسافران مرد فقط کمتر از 40 سال است در حالی که میانگین سنی مسافران زن حدود 33 سال است.
علاوه بر یافتن میانگین، از نمودار میله ای می توان برای محاسبه سایر مقادیر کل برای هر دسته نیز استفاده کرد. برای انجام این کار، باید تابع aggregate را به estimator. به عنوان مثال، می توانید انحراف معیار را برای سن هر جنسیت به صورت زیر محاسبه کنید:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.barplot(x='sex', y='age', data=dataset, estimator=np.std)
توجه داشته باشید، در اسکریپت بالا ما از std تابع کل از numpy کتابخانه برای محاسبه انحراف معیار برای سن مسافران مرد و زن. خروجی به شکل زیر است:

طرح شمارش
نمودار شمارش مشابه نمودار نواری است، با این حال تعداد دسته ها را در یک ستون خاص نمایش می دهد. به عنوان مثال، اگر بخواهیم تعداد مسافران مرد و زن را بشماریم، می توانیم با استفاده از نمودار شمارش به صورت زیر این کار را انجام دهیم:
sns.countplot(x='sex', data=dataset)
خروجی شمارش را به صورت زیر نشان می دهد:
خروجی:

طرح جعبه
نمودار جعبه برای نمایش توزیع داده های طبقه بندی شده در قالب چارک استفاده می شود. مرکز کادر مقدار میانه را نشان می دهد. مقدار از سبیل پایین تا پایین کادر اولین چارک را نشان می دهد. از پایین جعبه تا وسط جعبه، چارک دوم قرار دارد. از وسط جعبه تا بالای جعبه، ربع سوم و در نهایت از بالای جعبه تا سبیل بالایی آخرین ربع قرار دارد.
میتوانید در مورد چارکیها و نمودارهای جعبهای بیشتر مطالعه کنید این لینک.
حالا بیایید یک نمودار جعبه ای رسم کنیم که توزیع سن را با توجه به هر جنسیت نشان می دهد. شما باید ستون دسته بندی را به عنوان پارامتر اول (که در مورد ما جنسیت است) و ستون عددی (در مورد ما سن) را به عنوان پارامتر دوم ارسال کنید. در نهایت، مجموعه داده به عنوان پارامتر سوم ارسال می شود، به اسکریپت زیر نگاه کنید:
sns.boxplot(x='sex', y='age', data=dataset)
خروجی:

بیایید سعی کنیم طرح جعبه را برای زنان درک کنیم. چارک اول از حدود 5 شروع می شود و در 22 سالگی به پایان می رسد که به این معنی است که 25 درصد از مسافران بین 5 تا 25 سال سن دارند. چارک دوم از حدود 23 شروع می شود و در حدود 32 به پایان می رسد که به این معنی است که 25 درصد از مسافران بین 23 سال سن دارند. و 32. به همین ترتیب، چارک سوم بین 34 تا 42 سال شروع و پایان می یابد، بنابراین 25 درصد مسافران در این محدوده سن دارند و در نهایت چهارمین یا آخرین چارک از 43 شروع می شود و در حدود 65 سالگی به پایان می رسد.
اگر هر نقطه پرت یا مسافری وجود داشته باشد که به هیچ یک از چارک ها تعلق نداشته باشد، آنها را پرت می نامند و با نقطه نشان داده می شوند. روی طرح جعبه
می توانید با اضافه کردن یک لایه توزیع دیگر، نمودارهای جعبه خود را فانتزی تر کنید. به عنوان مثال، اگر می خواهید جعبه های علوفه مسافران هر دو جنس را به همراه اطلاعات در مورد زنده ماندن یا نبودن آنها ببینید، می توانید survived به عنوان ارزش به hue پارامتر مطابق شکل زیر:
sns.boxplot(x='sex', y='age', data=dataset, hue="survived")
خروجی:

اکنون علاوه بر اطلاعات مربوط به سن هر جنسیت، می توانید توزیع مسافرانی را که زنده مانده اند نیز مشاهده کنید. به عنوان مثال، می توانید ببینید که در بین مسافران مرد، روی به طور متوسط افراد جوان تر در مقایسه با افراد مسن تر زنده ماندند. به همین ترتیب، می بینید که تنوع سنی مسافران زن که زنده نمانده اند بسیار بیشتر از سن مسافران زن زنده مانده است.
طرح ویولن
طرح ویولن مشابه نمودار جعبه است، با این حال، طرح ویولن به ما امکان می دهد تمام اجزایی را که در واقع با نقطه داده مطابقت دارند نمایش دهیم. را violinplot() تابع برای ترسیم طرح ویولن استفاده می شود. مانند نمودار جعبه، پارامتر اول ستون طبقه بندی، پارامتر دوم ستون عددی و پارامتر سوم مجموعه داده است.
بیایید طرح ویولن را ترسیم کنیم که توزیع سن را با توجه به هر جنسیت نشان دهد.
sns.violinplot(x='sex', y='age', data=dataset)
خروجی:

از شکل بالا می بینید که نمودارهای ویولن اطلاعات بسیار بیشتری در مورد داده ها در مقایسه با نمودار جعبه ارائه می دهند. به جای ترسیم ربع، طرح ویولن به ما امکان می دهد تمام اجزایی را که در واقع با داده ها مطابقت دارند، ببینیم. منطقه ای که طرح ویولن ضخیم تر است، تعداد نمونه های بیشتری نسبت به سن دارد. به عنوان مثال، از طرح ویولن برای مردان، به وضوح مشهود است که تعداد مسافران با سن بین 20 تا 40 سال بیشتر از بقیه گروههای سنی است.
مانند نمودارهای جعبه، شما همچنین می توانید متغیر طبقه بندی دیگری را با استفاده از نمودار به نمودار ویولن اضافه کنید hue پارامتر مطابق شکل زیر:
sns.violinplot(x='sex', y='age', data=dataset, hue='survived')

اکنون می توانید اطلاعات زیادی را مشاهده کنید روی طرح ویولن به عنوان مثال، اگر به پایین طرح ویولن برای مردانی که زنده ماندهاند نگاه کنید (چپ-نارنجی)، میبینید که ضخیمتر از پایین طرح ویولن برای مردانی که زنده ماندهاند (چپ-آبی) است. ). این بدان معناست که تعداد مسافران مرد جوانی که زنده مانده اند بیشتر از مسافران مرد جوانی است که جان سالم به در نبرده اند. نقشه های ویولن اطلاعات زیادی را منتقل می کند، با این حال، روی نکته منفی این است که برای درک طرح های ویولن کمی زمان و تلاش لازم است.
به جای ترسیم دو نمودار متفاوت برای مسافرانی که جان سالم به در بردهاند و آنهایی که جان سالم به در بردهاند، میتوانید یک طرح ویولن را به دو نیمه تقسیم کنید، که در آن نیمی نشاندهنده زنده ماندن است و نیمی دیگر نشاندهنده مسافرانی است که زنده ماندهاند. برای این کار باید پاس کنید True به عنوان ارزش برای split پارامتر از violinplot() تابع. بیایید ببینیم چگونه می توانیم این کار را انجام دهیم:
sns.violinplot(x='sex', y='age', data=dataset, hue='survived', split=True)
خروجی به شکل زیر است:

اکنون به وضوح میتوانید مقایسه بین سن مسافرانی که جان سالم به در بردهاند و مسافرانی که نبردهاند را برای زن و مرد مشاهده کنید.
هر دو طرح ویولن و جعبه می توانند بسیار مفید باشند. با این حال، به عنوان یک قاعده کلی، اگر دادههای خود را به مخاطبان غیر فنی ارائه میدهید، نمودارهای جعبهای باید ترجیح داده شوند زیرا درک آنها آسان است. از طرف دیگر، اگر نتایج خود را به جامعه تحقیقاتی ارائه می دهید، استفاده از طرح ویولن برای صرفه جویی در فضا و انتقال اطلاعات بیشتر در زمان کمتر راحت تر است.
طرح نوار
نمودار نواری یک نمودار پراکنده ترسیم می کند که در آن یکی از متغیرها طبقه بندی می شود. ما نمودارهای پراکندگی را در نمودار مشترک و بخش های نمودار زوجی که در آن دو متغیر عددی داشتیم، دیده ایم. نمودار نواری متفاوت است به گونه ای که یکی از متغیرها در این حالت طبقه بندی می شود و برای هر دسته در متغیر طبقه بندی، نمودار پراکندگی را نسبت به ستون عددی مشاهده خواهید کرد.
را stripplot() تابع برای ترسیم طرح ویولن استفاده می شود. مانند نمودار جعبه، پارامتر اول ستون طبقه بندی، پارامتر دوم ستون عددی و پارامتر سوم مجموعه داده است. به اسکریپت زیر نگاه کنید:
sns.stripplot(x='sex', y='age', data=dataset)
خروجی:

شما می توانید نمودارهای پراکنده سن را هم برای مردان و هم برای زنان مشاهده کنید. نقاط داده مانند نوار به نظر می رسند. درک توزیع داده ها در این شکل دشوار است. برای درک بهتر داده ها، پاس کنید True برای jitter پارامتری که مقداری نویز تصادفی به داده ها اضافه می کند. به اسکریپت زیر نگاه کنید:
sns.stripplot(x='sex', y='age', data=dataset, jitter=True)
خروجی:

اکنون دید بهتری برای توزیع سن در بین جنسیت ها دارید.
مانند طرح های ویولن و جعبه، می توانید با استفاده از طرح نواری، یک ستون دسته بندی اضافی اضافه کنید hue پارامتر مطابق شکل زیر:
sns.stripplot(x='sex', y='age', data=dataset, jitter=True, hue='survived')

باز هم می توانید ببینید که امتیاز بیشتری برای مردانی که در نزدیکی انتهای طرح زنده مانده اند در مقایسه با آنهایی که زنده نمانده اند وجود دارد.
مانند طرح های ویولن، می توانیم طرح های نواری را نیز تقسیم کنیم. اسکریپت زیر را اجرا کنید:
sns.stripplot(x='sex', y='age', data=dataset, jitter=True, hue='survived', split=True)
خروجی:

اکنون به وضوح میتوانید تفاوت توزیع را برای سن مسافران مرد و زن زندهمانده و آنهایی که زنده ماندهاند، مشاهده کنید.
طرح ازدحام
طرح ازدحام ترکیبی از طرح نوار و ویولن است. در طرح های ازدحام، نقاط به گونه ای تنظیم می شوند که روی هم قرار نگیرند. بیایید یک طرح ازدحام برای توزیع سن بر اساس جنسیت ترسیم کنیم. را swarmplot() تابع برای ترسیم طرح ویولن استفاده می شود. مانند نمودار جعبه، پارامتر اول ستون طبقه بندی، پارامتر دوم ستون عددی و پارامتر سوم مجموعه داده است. به اسکریپت زیر نگاه کنید:
sns.swarmplot(x='sex', y='age', data=dataset)

به وضوح می بینید که نمودار بالا حاوی نقاط داده پراکنده مانند نمودار نواری است و نقاط داده با هم تداخل ندارند. در عوض آنها طوری تنظیم شده اند که دیدگاهی شبیه به طرح ویولن ارائه دهند.
بیایید ستون دسته بندی دیگری را با استفاده از نشانگر به نمودار ازدحام اضافه کنیم hue پارامتر.
sns.swarmplot(x='sex', y='age', data=dataset, hue='survived')
خروجی:

از خروجی، مشهود است که نسبت مردان زنده مانده کمتر از نسبت زنان زنده مانده است. از آنجایی که برای طرح مرد، نقاط آبی بیشتر و نقاط نارنجی کمتری وجود دارد. از سوی دیگر، برای ماده ها، نقاط نارنجی (بازمانده) بیشتر از نقاط آبی (بقای نشدن) وجود دارد. مشاهدات دیگر این است که در میان مردان کمتر از 10 سال، مسافران بیشتری در مقایسه با کسانی که زنده مانده بودند، زنده ماندند.
ما همچنین میتوانیم مانند طرحهای نواری و جعبهای، کرتهای ازدحام را تقسیم کنیم. برای این کار اسکریپت زیر را اجرا کنید:
sns.swarmplot(x='sex', y='age', data=dataset, hue='survived', split=True)
خروجی:

اکنون به وضوح می توانید ببینید که زنان بیشتری در مقایسه با مردان زنده مانده اند.
ترکیب طرح های ازدحام و ویولن
اگر مجموعه داده بزرگی دارید، نمودارهای Swarm توصیه نمی شوند، زیرا مقیاس آنها به خوبی انجام نمی شود زیرا باید هر نقطه داده را رسم کنند. اگر واقعاً طرح های ازدحام را دوست دارید، راه بهتر ترکیب دو طرح است. به عنوان مثال، برای ترکیب یک طرح ویولن با طرح ازدحام، باید اسکریپت زیر را اجرا کنید:
sns.violinplot(x='sex', y='age', data=dataset)
sns.swarmplot(x='sex', y='age', data=dataset, color='black')
خروجی:

در حالی که این مجموعه قصد دارد یک منبع دقیق باشد روی با استفاده از Seaborn، جزئیات زیادی وجود دارد که ما نمی توانیم در چند پست وبلاگ پوشش دهیم. همچنین تعداد زیادی کتابخانه تجسمی دیگر برای پایتون وجود دارد که دارای ویژگی هایی هستند که فراتر از آنچه Seaborn می تواند انجام دهد، می باشد. برای یک راهنمای عمیق تر برای تجسم داده ها در پایتون با استفاده از Seabor و همچنین 8 کتابخانه دیگر، بررسی کنید تجسم داده ها در پایتون.
نتیجه
متولد دریا یک کتابخانه تجسم داده پیشرفته ساخته شده است روی بالای کتابخانه Matplotlib. در این مقاله به روش ترسیم نمودارهای توزیعی و طبقه بندی با استفاده از کتابخانه Seaborn پرداختیم. این قسمت 1 از سری مقاله است روی متولد دریا. در مقاله دوم این مجموعه، خواهیم دید که چگونه با عملکردهای شبکه در Seaborn بازی می کنیم و چگونه می توانیم نمودارهای ماتریس و رگرسیون را در Seaborn ترسیم کنیم.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-25 23:03:03
