از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
یک یادگیری ماشینی معمولی process شامل آموزش مدل های مختلف است روی مجموعه داده و انتخاب یکی با بهترین عملکرد. با این حال، ارزیابی عملکرد الگوریتم همیشه یک کار مستقیم نیست. چندین عامل وجود دارد که می تواند به شما در تعیین بهترین عملکرد الگوریتم کمک کند. یکی از این عوامل عملکرد است روی مجموعه اعتبارسنجی متقاطع و عامل دیگر انتخاب پارامترهای یک الگوریتم است.
در این مقاله به بررسی دقیق این دو عامل خواهیم پرداخت. ابتدا بررسی خواهیم کرد که اعتبار سنجی متقاطع چیست، چرا لازم است و چگونه آن را از طریق پایتون انجام دهیم Scikit-Learn کتابخانه سپس حرکت خواهیم کرد روی به الگوریتم جستجوی شبکه و ببینید که چگونه می توان از آن برای انتخاب خودکار بهترین پارامترها برای یک الگوریتم استفاده کرد.
اعتبار سنجی متقابل
به طور معمول در یک یادگیری ماشینی process، داده ها به مجموعه های آموزشی و آزمایشی تقسیم می شوند. سپس مجموعه آموزشی برای آموزش مدل و مجموعه تست برای ارزیابی عملکرد یک مدل استفاده می شود. با این حال، این رویکرد ممکن است منجر به مشکلات واریانس شود. به عبارت ساده تر، مسئله واریانس به سناریویی اشاره دارد که دقت ما به دست آمده است روی یک تست با دقت به دست آمده بسیار متفاوت است روی مجموعه تست دیگری با استفاده از همان الگوریتم.
راه حل این مشکل استفاده است K-Fold Cross-Validation برای ارزیابی عملکرد که در آن K هر عدد باشد. این process K-Fold Cross-Validation ساده است. داده ها را به K fold تقسیم می کنید. در خارج از چینهای K، مجموعههای K-1 برای تمرین استفاده میشوند، در حالی که مجموعه باقیمانده برای آزمایش استفاده میشود. الگوریتم K بار آموزش و آزمایش می شود، هر بار یک مجموعه جدید به عنوان مجموعه آزمایشی استفاده می شود در حالی که مجموعه های باقی مانده برای آموزش استفاده می شود. در نهایت، نتیجه K-Fold Cross-Validation میانگین نتایج به دست آمده است روی هر مجموعه.
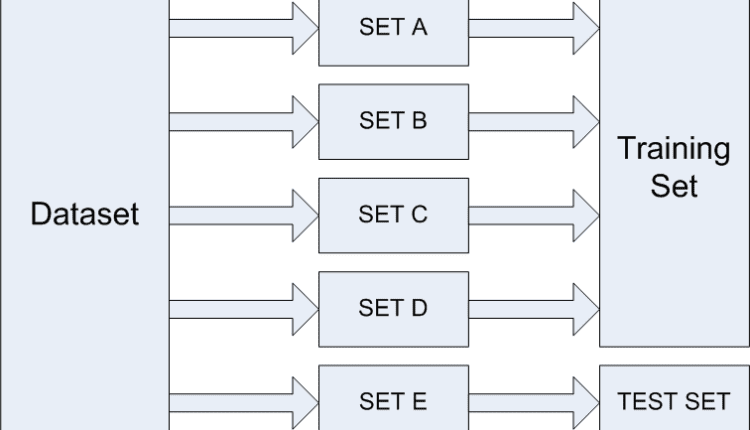
فرض کنید می خواهیم اعتبار سنجی متقاطع 5 برابری را انجام دهیم. برای انجام این کار، داده ها به 5 مجموعه تقسیم می شوند، به عنوان مثال ما آنها را SET A، SET B، SET C، SET D و SET E می نامیم. الگوریتم K بار آموزش و آزمایش می شود. در قسمت اول، از SET A تا SET D به عنوان مجموعه آموزشی و از SET E به عنوان مجموعه تست استفاده می شود که در شکل زیر نشان داده شده است:

در قسمت دوم، از SET A، SET B، SET C و SET E برای آموزش و از SET D به عنوان تست استفاده می شود. این process ادامه می یابد تا زمانی که هر مجموعه حداقل یک بار برای آموزش و یک بار برای تست استفاده شود. نتیجه نهایی میانگین نتایج به دست آمده با استفاده از تمام چین ها است. به این ترتیب می توانیم از شر واریانس خلاص شویم. با استفاده از انحراف معیار نتایج به دست آمده از هر برابر، در واقع می توانیم واریانس را در نتیجه کلی پیدا کنیم.
اعتبارسنجی متقابل با Scikit-Learn
در این بخش از اعتبار سنجی متقاطع برای ارزیابی عملکرد الگوریتم جنگل تصادفی برای طبقه بندی استفاده خواهیم کرد. مشکلی که ما می خواهیم حل کنیم این است که کیفیت شراب را پیش بینی کنیم روی 12 ویژگی جزئیات مجموعه داده در لینک زیر موجود است:
https://archive.ics.uci.edu/ml/datasets/wine+quality
ما در این مقاله فقط از داده های شراب قرمز استفاده می کنیم.
این مراحل را برای پیاده سازی اعتبار متقاطع با استفاده از Scikit-Learn دنبال کنید:
1. واردات کتابخانه های مورد نیاز
کد زیر تعدادی از کتابخانه های مورد نیاز را وارد می کند:
import pandas as pd
import numpy as np
2. وارد کردن مجموعه داده
مجموعه داده را دانلود کنید که به صورت آنلاین در این لینک موجود است:
https://www.kaggle.com/piyushgoyal443/red-wine-dataset
هنگامی که آن را دانلود کردیم، به خاطر این مقاله، فایل را در پوشه “Datasets” درایو “D” خود قرار دادیم. نام مجموعه داده “winequality-red.csv” است. توجه داشته باشید که باید مسیر فایل را تغییر دهید تا با مکانی که فایل را در آن ذخیره کرده اید مطابقت داشته باشد روی کامپیوتر شما.
دستور زیر را اجرا کنید import مجموعه داده:
dataset = pd.read_csv(r"D:/Datasets/winequality-red.csv", sep=';')
مجموعه داده نیمه ویرگول از هم جدا شده است، بنابراین ما “;” را پاس کرده ایم. به پارامتر “sep” نسبت داده شود تا پانداها بتوانند فایل را به درستی تجزیه کنند.
3. تجزیه و تحلیل داده ها
اسکریپت زیر را برای دریافت نمای کلی از داده ها اجرا کنید:
dataset.head()
خروجی به شکل زیر است:
| اسیدیته ثابت | اسیدیته فرار | اسید سیتریک | قند باقی مانده | کلریدها | دی اکسید گوگرد آزاد | دی اکسید گوگرد کل | تراکم | pH | سولفات ها | الکل | کیفیت | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
| 1 | 7.8 | 0.88 | 0.00 | 2.6 | 0.098 | 25.0 | 67.0 | 0.9968 | 3.20 | 0.68 | 9.8 | 5 |
| 2 | 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15.0 | 54.0 | 0.9970 | 3.26 | 0.65 | 9.8 | 5 |
| 3 | 11.2 | 0.28 | 0.56 | 1.9 | 0.075 | 17.0 | 60.0 | 0.9980 | 3.16 | 0.58 | 9.8 | 6 |
| 4 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
4. پیش پردازش داده ها
اسکریپت زیر را برای تقسیم داده ها به مجموعه برچسب ها و ویژگی ها اجرا کنید.
X = dataset.iloc(:, 0:11).values
y = dataset.iloc(:, 11).values
از آنجایی که ما از اعتبارسنجی متقاطع استفاده می کنیم، نیازی نیست که داده های خود را به مجموعه های آموزشی و آزمایشی تقسیم کنیم. ما تمام داده های مجموعه آموزشی را می خواهیم تا بتوانیم اعتبار سنجی متقاطع را اعمال کنیم روی که ساده ترین راه برای انجام این کار، تنظیم مقدار برای test_size پارامتر به 0. این همه داده های مجموعه آموزشی را به صورت زیر برمی گرداند:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0, random_state=0)
5. مقیاس گذاری داده ها
اگر به مجموعه داده نگاه کنید، متوجه خواهید شد که به خوبی مقیاس بندی نشده است. به عنوان مثال، ستون “اسیدیته فرار” و “اسید سیتریک” دارای مقادیری بین 0 و 1 هستند، در حالی که بسیاری از بقیه ستون ها مقادیر بالاتری دارند. بنابراین، قبل از آموزش الگوریتم، باید داده های خود را کوچک کنیم.
در اینجا ما از StandardScalar کلاس
from sklearn.preprocessing import StandardScaler
feature_scaler = StandardScaler()
X_train = feature_scaler.fit_transform(X_train)
X_test = feature_scaler.transform(X_test)
6. آموزش و اعتبارسنجی متقابل
اولین مرحله در مرحله آموزش و اعتبارسنجی متقابل ساده است. شما فقط باید import کلاس الگوریتم از sklearn کتابخانه مطابق شکل زیر:
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators=300, random_state=0)
در مرحله بعد، برای پیاده سازی اعتبار متقاطع، cross_val_score روش از sklearn.model_selection می توان از کتابخانه استفاده کرد. این cross_val_score دقت را برای تمام چین ها برمی گرداند. مقادیر برای 4 پارامتر لازم است به پارامتر ارسال شود cross_val_score کلاس پارامتر اول برآوردگر است که اساساً الگوریتمی را که میخواهید برای اعتبارسنجی متقاطع استفاده کنید مشخص میکند. پارامترهای دوم و سوم X و y، حاوی X_train و y_train داده ها یعنی ویژگی ها و برچسب ها. در نهایت تعداد تاها به عدد منتقل می شود cv پارامتر همانطور که در کد زیر نشان داده شده است:
from sklearn.model_selection import cross_val_score
all_accuracies = cross_val_score(estimator=classifier, X=X_train, y=y_train, cv=5)
هنگامی که این را اجرا کردید، اجازه دهید به سادگی print دقت برای پنج برابر توسط cross_val_score روش با تماس print روی all_accuracies.
print(all_accuracies)
خروجی:
( 0.72360248 0.68535826 0.70716511 0.68553459 0.68454259 )
برای پیدا کردن میانگین تمام دقت ها، ساده استفاده کنید mean() روش شی برگردانده شده توسط cross_val_score روشی که در زیر نشان داده شده است:
print(all_accuracies.mean())
مقدار متوسط 0.6972 یا 69.72٪ است.
در نهایت اجازه دهید انحراف معیار داده ها را پیدا کنیم تا درجه واریانس را در نتایج به دست آمده توسط مدل خود ببینیم. برای انجام این کار، با شماره تماس بگیرید std() روش روی را all_accuracies هدف – شی.
print(all_accuracies.std())
نتیجه: 0.01572 است که 1.57٪ است. این بسیار کم است، به این معنی که مدل ما واریانس بسیار پایینی دارد، که در واقع بسیار خوب است، زیرا به این معنی است که پیشبینی به دست آمده روی یک مجموعه تست تصادفی نیست. در عوض، مدل کمابیش مشابه عمل خواهد کرد روی تمام مجموعه های تست
جستجوی شبکه برای انتخاب پارامتر
یک مدل یادگیری ماشینی دو نوع پارامتر دارد. پارامترهای نوع اول، پارامترهایی هستند که از طریق یک مدل یادگیری ماشینی یاد می گیرند، در حالی که پارامترهای نوع دوم، پارامترهایپر هستند که به مدل یادگیری ماشینی منتقل می کنیم.
در بخش آخر ضمن پیشبینی کیفیت شراب، از الگوریتم جنگل تصادفی استفاده کردیم. تعداد برآوردگرهایی که برای الگوریتم استفاده کردیم 300 عدد بود. به طور مشابه در الگوریتم KNN باید مقدار K و برای الگوریتم SVM باید نوع هسته را مشخص کنیم. این برآوردگرها – مقدار K و Kernel – همه انواع پارامترهای hyper هستند.
به طور معمول ما به صورت تصادفی مقدار این پارامترهای هایپر را تنظیم می کنیم و می بینیم که چه پارامترهایی بهترین عملکرد را دارند. با این حال انتخاب تصادفی پارامترها برای الگوریتم می تواند جامع باشد.
همچنین، مقایسه عملکرد الگوریتم های مختلف با تنظیم تصادفی پارامترهای هایپر آسان نیست، زیرا ممکن است یک الگوریتم بهتر از دیگری با مجموعه پارامترهای مختلف عمل کند. و اگر پارامترها تغییر کنند، الگوریتم ممکن است بدتر از سایر الگوریتم ها عمل کند.
بنابراین، به جای انتخاب تصادفی مقادیر پارامترها، یک رویکرد بهتر توسعه الگوریتمی است که به طور خودکار بهترین پارامترها را برای یک مدل خاص پیدا کند. Grid Search یکی از این الگوریتمها است.
جستجوی شبکه با Scikit-Learn
بیایید الگوریتم جستجوی شبکه ای را با کمک یک مثال پیاده سازی کنیم. اسکریپت این قسمت باید بعد از اسکریپتی که در قسمت آخر ایجاد کردیم اجرا شود.
برای پیاده سازی الگوریتم Grid Search باید import GridSearchCV کلاس از sklearn.model_selection کتابخانه
اولین قدمی که باید انجام دهید این است که یک فرهنگ لغت از تمام پارامترها و مجموعه مقادیر مربوط به آنها ایجاد کنید که می خواهید برای بهترین عملکرد آزمایش کنید. نام آیتم های فرهنگ لغت با نام پارامتر و مقدار مربوط به لیست مقادیر پارامتر است.
بیایید یک فرهنگ لغت از پارامترها و مقادیر مربوط به آنها برای الگوریتم جنگل تصادفی خود ایجاد کنیم. جزئیات تمام پارامترهای الگوریتم جنگل تصادفی در دسترس است اسناد Scikit-Learn.
برای این کار کد زیر را اجرا کنید:
grid_param = {
'n_estimators': (100, 300, 500, 800, 1000),
'criterion': ('gini', 'entropy'),
'bootstrap': (True, False)
}
به کد بالا با دقت نگاه کنید. در اینجا ما ایجاد می کنیم grid_param فرهنگ لغت با سه پارامتر n_estimators، criterion، و bootstrap. مقادیر پارامتری که می خواهیم امتحان کنیم در لیست ارسال می شوند. به عنوان مثال، در اسکریپت بالا میخواهیم بفهمیم که کدام مقدار (از 100، 300، 500، 800 و 1000) بالاترین دقت را دارد.
به طور مشابه، ما می خواهیم پیدا کنیم که کدام مقدار بالاترین عملکرد را برای آن دارد criterion پارامتر: “gini” یا “آنتروپی”؟ الگوریتم Grid Search اساساً تمام ترکیبات ممکن از مقادیر پارامتر را امتحان می کند و ترکیب را با بالاترین دقت برمی گرداند. به عنوان مثال، در مورد فوق، الگوریتم 20 ترکیب (5 x 2 x 2 = 20) را بررسی می کند.
الگوریتم جستجوی گرید می تواند بسیار کند باشد، به دلیل وجود تعداد زیادی از ترکیبات برای آزمایش. علاوه بر این، اعتبار متقاطع زمان اجرا و پیچیدگی را بیشتر میکند.
هنگامی که فرهنگ لغت پارامتر ایجاد شد، مرحله بعدی ایجاد یک نمونه از آن است GridSearchCV کلاس شما باید مقادیری را برای estimator پارامتر، که اساساً الگوریتمی است که می خواهید اجرا کنید. این param_grid پارامتر دیکشنری پارامتر را می گیرد که ما به عنوان پارامتر ایجاد کردیم scoring پارامتر معیارهای عملکرد را می گیرد cv پارامتر مربوط به تعداد تاها، که در مورد ما 5 است، و در نهایت برابر است n_jobs پارامتر به تعداد CPU هایی که می خواهید برای اجرا استفاده کنید اشاره دارد. مقدار -1 برای n_jobs پارامتر به معنای استفاده از تمام توان محاسباتی موجود است. اگر تعداد زیادی داده دارید، این می تواند مفید باشد.
به کد زیر دقت کنید:
gd_sr = GridSearchCV(estimator=classifier,
param_grid=grid_param,
scoring='accuracy',
cv=5,
n_jobs=-1)
از وقتی که GridSearchCV کلاس مقداردهی اولیه می شود، آخرین مرحله فراخوانی آن است fit متد کلاس را بگذرانید و مجموعه آموزش و تست را همانطور که در کد زیر نشان داده شده است، پاس کنید:
gd_sr.fit(X_train, y_train)
اجرای این روش ممکن است کمی طول بکشد زیرا ما 20 ترکیب از پارامترها و اعتبارسنجی متقاطع 5 برابری داریم. بنابراین الگوریتم در مجموع 100 بار اجرا می شود.
پس از اتمام اجرای متد، مرحله بعدی بررسی پارامترهایی است که بالاترین دقت را برمیگردانند. برای انجام این کار، print را sr.best_params_ ویژگی از GridSearchCV شیء، همانطور که در زیر نشان داده شده است:
best_parameters = gd_sr.best_params_
print(best_parameters)
خروجی:
{'bootstrap': True, 'criterion': 'gini', 'n_estimators': 1000}
نتیجه نشان می دهد که بیشترین دقت زمانی حاصل می شود که n_estimators 1000 هستند bootstrap است True و criterion “جینی” است.
توجه داشته باشید: ایده خوبی است که تعداد بیشتری از برآوردگرها را اضافه کنید و ببینید آیا عملکرد بیشتر از بالاترین مقدار مجاز افزایش می یابد. n_estimators انتخاب شد.
آخرین و آخرین مرحله الگوریتم Grid Search، یافتن دقت به دست آمده با استفاده از بهترین پارامترها است. قبلاً میانگین دقت 69.72 درصد با 300 داشتیم n_estimators.
برای یافتن بهترین دقت به دست آمده، کد زیر را اجرا کنید:
best_result = gd_sr.best_score_
print(best_result)
دقت به دست آمده: 0.6985 از 69.85٪ است که فقط کمی بهتر از 69.72٪ است. برای بهبود بیشتر این امر، خوب است مقادیر دیگر پارامترهای الگوریتم جنگل تصادفی، مانند max_features، max_depth، max_leaf_nodesو غیره را ببینید که آیا دقت بیشتر بهبود می یابد یا خیر.
نتیجه
در این مقاله ما دو تکنیک بسیار رایج برای ارزیابی عملکرد و انتخاب مدل یک الگوریتم را مطالعه کردیم. K-Fold Cross-Validation میتواند برای ارزیابی عملکرد یک مدل با مدیریت مشکل واریانس مجموعه نتایج استفاده شود. علاوه بر این، برای شناسایی بهترین الگوریتم و بهترین پارامترها، میتوان از الگوریتم Grid Search استفاده کرد.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-27 18:29:04
