از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



چگونه می توان قابلیت اطمینان یک مدل هوش مصنوعی همه منظوره را قبل از استقرار آن ارزیابی کرد
زمان لازم برای مطالعه: 5 دقیقه
مدل های بنیادی، مدل های عظیم یادگیری عمیق هستند که از قبل آموزش دیده اند روی حجم عظیمی از داده های همه منظوره و بدون برچسب. آنها را می توان برای کارهای مختلفی مانند تولید تصاویر یا پاسخ به سؤالات مشتری اعمال کرد.
اما این مدل ها که به عنوان ستون فقرات ابزارهای قدرتمند هوش مصنوعی مانند ChatGPT و DALL-E عمل می کنند، می توانند اطلاعات نادرست یا گمراه کننده را ارائه دهند. در یک موقعیت بحرانی ایمنی، مانند نزدیک شدن عابر پیاده به خودروی خودران، این اشتباهات می تواند عواقب جدی داشته باشد.
برای کمک به جلوگیری از چنین اشتباهاتی، محققان MIT و آزمایشگاه هوش مصنوعی MIT-IBM Watson، تکنیکی را برای تخمین قابلیت اطمینان مدلهای پایه قبل از استفاده از یک کار خاص توسعه دادند.
آنها این کار را با در نظر گرفتن مجموعه ای از مدل های فونداسیون انجام می دهند که کمی با یکدیگر متفاوت هستند. سپس از الگوریتم خود برای ارزیابی سازگاری نمایش هایی که هر مدل در مورد نقطه داده آزمایشی یکسان یاد می گیرد، استفاده می کنند. اگر نمایش ها سازگار باشند، به این معنی است که مدل قابل اعتماد است.
هنگامی که آنها تکنیک خود را با روش های پایه پیشرفته مقایسه کردند، در به دست آوردن قابلیت اطمینان مدل های پایه بهتر بود. روی انواع وظایف طبقه بندی پایین دستی
کسی می تواند از این تکنیک برای تصمیم گیری در مورد استفاده از یک مدل در یک محیط خاص، بدون نیاز به آزمایش آن استفاده کند روی یک مجموعه داده در دنیای واقعی این می تواند به ویژه زمانی مفید باشد که مجموعه داده ها ممکن است به دلیل نگرانی های مربوط به حفظ حریم خصوصی در دسترس نباشند، مانند تنظیمات مراقبت های بهداشتی. علاوه بر این، این تکنیک می تواند برای رتبه بندی مدل ها بر اساس استفاده شود روی امتیازات قابلیت اطمینان، کاربر را قادر می سازد تا بهترین مورد را برای وظیفه خود انتخاب کند.
«همه مدلها ممکن است اشتباه باشند، اما مدلهایی که میدانند چه زمانی اشتباه هستند، مفیدتر هستند. مشکل کمی کردن عدم قطعیت یا قابلیت اطمینان برای این مدلهای پایه چالش برانگیزتر است زیرا بازنماییهای انتزاعی آنها مقایسه دشواری است. نوید عزیزان، نویسنده ارشد، استادیار استر و هارولد ای. ادگرتون در بخش مهندسی مکانیک MIT و مؤسسه دادهها، سیستمها و مؤسسه دادهها، سیستمها و دادههای ورودی، میگوید: روش ما به فرد اجازه میدهد تا میزان قابل اعتماد بودن یک مدل نمایشی را برای هر داده ورودی مشخص کند. جامعه (IDSS) و یکی از اعضای آزمایشگاه اطلاعات و سیستم های تصمیم گیری (LIDS).
او ملحق شده است روی مقاله ای درباره کار توسط یانگ جین پارک، نویسنده اصلی، دانشجوی کارشناسی ارشد LIDS. هائو وانگ، دانشمند محقق در آزمایشگاه هوش مصنوعی واتسون MIT-IBM. و شروین اردشیر، پژوهشگر ارشد در نتفلیکس. مقاله در کنفرانس ارائه خواهد شد روی عدم قطعیت در هوش مصنوعی
سنجش اجماع
مدل های سنتی یادگیری ماشینی برای انجام یک کار خاص آموزش می بینند. این مدلها معمولاً بر اساس یک پیشبینی مشخص انجام میدهند روی یک ورودی به عنوان مثال، مدل ممکن است به شما بگوید که آیا یک تصویر خاص شامل گربه یا سگ است. در این مورد، ارزیابی قابلیت اطمینان میتواند با نگاهی به پیشبینی نهایی باشد تا ببینیم آیا مدل درست است یا خیر.
اما مدل های فونداسیون متفاوت است. این مدل با استفاده از دادههای عمومی از قبل آموزش داده شده است، در شرایطی که سازندگان آن همه وظایف پاییندستی را نمیدانند. کاربران پس از آموزش آن را با وظایف خاص خود تطبیق می دهند.
برخلاف مدلهای سنتی یادگیری ماشینی، مدلهای پایه خروجیهای بتنی مانند برچسبهای «گربه» یا «سگ» نمیدهند. در عوض، آنها یک بازنمایی انتزاعی را بر اساس تولید می کنند روی یک نقطه داده ورودی
برای ارزیابی قابلیت اطمینان یک مدل پایه، محققان از یک رویکرد مجموعه ای با آموزش چندین مدل استفاده کردند که دارای ویژگی های مشترک هستند اما کمی با یکدیگر متفاوت هستند.
ایده ما مانند اندازه گیری اجماع است. پارک میگوید: اگر همه آن مدلهای پایه، نمایشهای ثابتی برای هر داده در مجموعه داده ما ارائه دهند، میتوان گفت که این مدل قابل اعتماد است.
اما آنها با یک مشکل مواجه شدند: چگونه می توانند بازنمایی های انتزاعی را با هم مقایسه کنند؟
او میافزاید: «این مدلها فقط یک بردار را تولید میکنند که از برخی اعداد تشکیل شده است، بنابراین ما نمیتوانیم به راحتی آنها را با هم مقایسه کنیم».
آنها این مشکل را با استفاده از ایده ای به نام ثبات همسایگی حل کردند.
برای رویکرد خود، محققان مجموعه ای از نقاط مرجع قابل اعتماد را برای آزمایش آماده می کنند روی مجموعه مدل ها سپس، برای هر مدل، نقاط مرجع واقع در نزدیکی نمایش آن مدل از نقطه آزمایش را بررسی می کنند.
با مشاهده همسانی نقاط مجاور، آنها می توانند پایایی مدل ها را تخمین بزنند.
تراز کردن نمایندگی ها
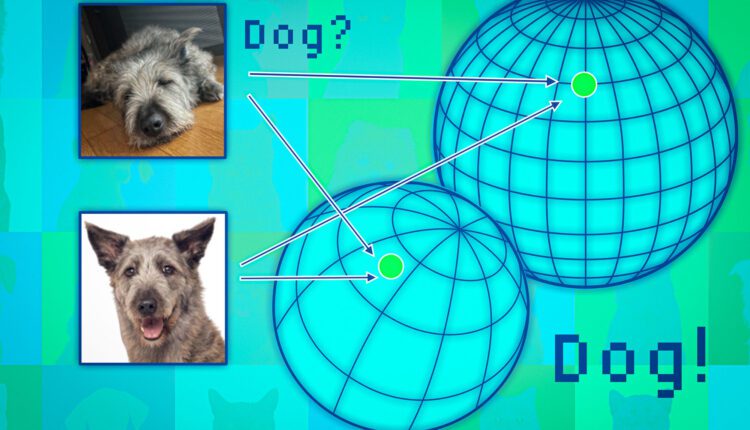
مدل های بنیادی، نقاط داده را به فضایی که به عنوان فضای بازنمایی شناخته می شود، نگاشت می کنند. یکی از راه های اندیشیدن به این فضا به صورت یک کره است. هر مدل نقاط داده مشابهی را در همان قسمت کره خود ترسیم می کند، بنابراین تصاویر گربه ها در یک مکان و تصاویر سگ ها در مکان دیگر قرار می گیرند.
اما هر مدلی میتواند حیوانات را در کرهی خود به طور متفاوتی ترسیم کند، بنابراین گربهها ممکن است در نزدیکی قطب جنوب یک کره گروهبندی شوند، مدل دیگری میتواند گربهها را در جایی در نیمکره شمالی ترسیم کند.
محققان از نقاط مجاور مانند لنگرها برای تراز کردن آن کره ها استفاده می کنند تا بتوانند نمایش ها را با هم مقایسه کنند. اگر همسایگان یک نقطه داده در چندین نمایش ثابت باشند، باید در مورد قابلیت اطمینان خروجی مدل برای آن نقطه مطمئن بود.
وقتی این رویکرد را آزمایش کردند روی طیف گسترده ای از وظایف طبقه بندی، آنها دریافتند که بسیار سازگارتر از خطوط پایه است. بهعلاوه، با چالشبرانگیز کردن نقاط آزمون که باعث شکست سایر روشها میشد، از بین نرفت.
علاوه بر این، رویکرد آنها می تواند برای ارزیابی قابلیت اطمینان هر داده ورودی مورد استفاده قرار گیرد، بنابراین می توان ارزیابی کرد که یک مدل برای یک نوع خاص از افراد، مانند یک بیمار با ویژگی های خاص، چقدر خوب کار می کند.
وانگ میگوید: «حتی اگر همه مدلها به طور کلی عملکرد متوسطی داشته باشند، از دیدگاه فردی، شما مدلی را ترجیح میدهید که برای آن فرد بهترین کارایی را داشته باشد».
با این حال، یک محدودیت ناشی از این واقعیت است که آنها باید مجموعه ای از مدل های پایه را آموزش دهند که از نظر محاسباتی گران است. در آینده، آنها قصد دارند راه های کارآمدتری برای ساخت چندین مدل پیدا کنند، شاید با استفاده از اغتشاشات کوچک یک مدل واحد.
با روند فعلی استفاده از مدلهای پایه برای جاسازیهای آنها برای پشتیبانی از وظایف مختلف پاییندستی – از تنظیم دقیق تا بازیابی نسل افزوده – موضوع کمیسازی عدم قطعیت در سطح نمایش بهعنوان جاسازیها بهطور فزایندهای مهم، اما چالش برانگیز است. روی خودشون هیچ پایه ای ندارند مارکو پاوون، دانشیار دپارتمان هوانوردی و فضانوردی در دانشگاه استنفورد، میگوید آنچه در عوض اهمیت دارد این است که چگونه تعبیههای ورودیهای مختلف با یکدیگر مرتبط هستند، ایدهای که این کار به خوبی از طریق امتیاز همسایگی پیشنهادی به تصویر میکشد. درگیر این کار نیست “این یک گام امیدوارکننده به سمت تعیین کمیت عدم قطعیت با کیفیت بالا برای مدلهای جاسازی شده است، و من از دیدن برنامههای افزودنی آینده که میتوانند بدون نیاز به مجموعهای از مدلها عمل کنند تا واقعاً این رویکرد را برای مقیاسبندی به مدلهای اندازه پایه عمل کنند، هیجانزده هستم.”
این کار تا حدی توسط آزمایشگاه هوش مصنوعی MIT-IBM Watson AI، MathWorks و آمازون تامین می شود.
منبع: https://news.mit.edu/1403/how-assess-general-purpose-ai-models-reliability-its-deployed
برای نگارش بخشهایی از این متن ممکن است از ترجمه ماشینی یا هوش مصنوعی GPT استفاده شده باشد
لطفا در صورت وجود مشکل در متن یا مفهوم نبودن توضیحات، از طریق دکمه گزارش نوشتار یا درج نظر روی این مطلب ما را از جزییات مشکل مشاهده شده مطلع کنید تا به آن رسیدگی کنیم
لطفا در صورت وجود مشکل در متن یا مفهوم نبودن توضیحات، از طریق دکمه گزارش نوشتار یا درج نظر روی این مطلب ما را از جزییات مشکل مشاهده شده مطلع کنید تا به آن رسیدگی کنیم
زمان انتشار: 1403-07-16 18:57:06
