از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



زمان لازم برای مطالعه: 4 دقیقه
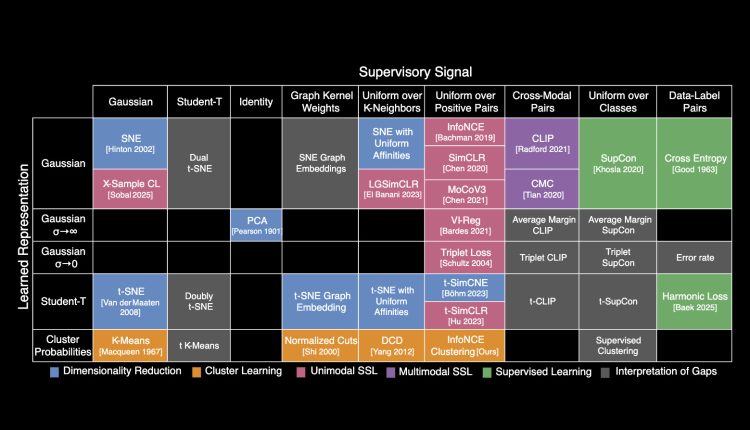
محققان MIT یک جدول تناوبی ایجاد کرده اند که نشان می دهد بیش از 20 الگوریتم یادگیری ماشین کلاسیک چگونه به هم وصل شده است. چارچوب جدید نور را روشن می کند روی چگونه دانشمندان می توانند استراتژی هایی را از روشهای مختلف برای بهبود مدل های هوش مصنوعی موجود یا روش های جدید فیوز کنند.
به عنوان مثال ، محققان از چارچوب خود برای ترکیب عناصر دو الگوریتم مختلف برای ایجاد یک الگوریتم جدید طبقه بندی تصویر استفاده کردند که 8 درصد بهتر از رویکردهای پیشرفته فعلی را انجام می داد.
جدول تناوبی از یک ایده کلیدی ناشی می شود: همه این الگوریتم ها نوع خاصی از رابطه بین نقاط داده را می آموزند. در حالی که هر الگوریتم ممکن است به روشی کمی متفاوت انجام شود ، ریاضیات اصلی در پشت هر رویکرد یکسان است.
ساختمان روی این بینش ها ، محققان یک معادله متحد را مشخص کردند که زیربنای بسیاری از الگوریتم های کلاسیک هوش مصنوعی است. آنها از این معادله برای تغییر روشهای محبوب و ترتیب آنها در یک جدول استفاده کردند و هر کدام را طبقه بندی کردند روی روابط تقریبی آن را یاد می گیرد.
دقیقاً مانند جدول تناوبی عناصر شیمیایی ، که در ابتدا دارای مربع های خالی بود که بعداً توسط دانشمندان پر شد ، جدول تناوبی یادگیری ماشین نیز دارای فضاهای خالی است. این فضاها پیش بینی می کنند که الگوریتم ها در کجا باید وجود داشته باشند ، اما هنوز کشف نشده اند.
این جدول به محققان می دهد تا الگوریتم های جدید را بدون نیاز به کشف مجدد ایده ها از رویکردهای قبلی طراحی کنند ، می گوید: سایهن آلشاماری ، دانشجوی فارغ التحصیل MIT و نویسنده اصلی یک مقاله روی این چارچوب جدید
Alshammari می افزاید: “این فقط یک استعاره نیست.” “ما شروع به یادگیری ماشین به عنوان سیستمی با ساختار می کنیم که فضایی است که می توانیم به جای اینکه فقط راه خود را حدس بزنیم ، کشف کنیم.”
به او پیوسته است روی مقاله جان هرشی ، محقق Google AI Perception ؛ اکسل فلدمان ، دانشجوی فارغ التحصیل MIT ؛ ویلیام فریمن ، توماس و گرد پرکینز استاد مهندسی برق و علوم کامپیوتر و عضو آزمایشگاه علوم کامپیوتر و اطلاعات مصنوعی (CSAIL) ؛ و نویسنده ارشد مارک همیلتون ، دانشجوی فارغ التحصیل MIT و مدیر ارشد مهندسی در مایکروسافت. این تحقیق در کنفرانس بین المللی ارائه خواهد شد روی یادگیری بازنمایی.
یک معادله تصادفی
محققان تصمیم نگرفتند یک جدول تناوبی از یادگیری ماشین ایجاد کنند.
پس از پیوستن به آزمایشگاه فریمن ، Alshammari شروع به مطالعه خوشه بندی کرد ، یک روش یادگیری ماشین که با یادگیری سازماندهی تصاویر مشابه در خوشه های مجاور ، تصاویر را طبقه بندی می کند.
او متوجه شد که الگوریتم خوشه بندی که در حال مطالعه بود ، مشابه الگوریتم یادگیری ماشین کلاسیک دیگر به نام یادگیری متضاد بود و شروع به حفر عمیق تر در ریاضیات کرد. Alshammari دریافت که این دو الگوریتم متفاوت می توانند با استفاده از همان معادله اساسی تغییر شکل دهند.
هامیلتون می گوید: “ما تقریباً به طور تصادفی به این معادله وحدت رسیدیم. هنگامی که Shaden فهمید که این دو روش را به هم وصل می کند ، ما تازه شروع به رویای روش های جدید برای وارد کردن این چارچوب کردیم. تقریباً هر یک که سعی کردیم به آن اضافه شود.”
چارچوبی که آنها ایجاد کرده اند ، یادگیری متضاد (I-Con) ، نشان می دهد که چگونه می توان انواع الگوریتم ها را از طریق لنز این معادله متحد مشاهده کرد. این شامل همه چیز از الگوریتم های طبقه بندی است که می توانند SPAM را به الگوریتم های یادگیری عمیق که LLMS را قدرت می دهند ، تشخیص دهند.
معادله توصیف می کند که چگونه چنین الگوریتم ها بین نقاط داده واقعی ارتباط برقرار می کنند و سپس آن اتصالات را در داخل تقریبی می کنند.
هر الگوریتم با هدف به حداقل رساندن میزان انحراف بین اتصالات مورد نظر برای تقریبی و اتصالات واقعی در داده های آموزشی خود به حداقل می رسد.
آنها تصمیم گرفتند I-Con را در یک جدول تناوبی سازماندهی کنند تا الگوریتم های مبتنی بر طبقه بندی شوند روی چگونگی اتصال نقاط در مجموعه داده های واقعی و روشهای اصلی الگوریتم ها می توانند این اتصالات را تقریبی کنند.
آلشماری می گوید: “کار به تدریج انجام شد ، اما هنگامی که ساختار کلی این معادله را شناسایی کردیم ، افزودن روش های بیشتر به چارچوب ما آسانتر بود.”
ابزاری برای کشف
همانطور که آنها جدول را ترتیب دادند ، محققان شروع به دیدن شکاف هایی کردند که الگوریتم ها می توانند وجود داشته باشند ، اما هنوز اختراع نشده اند.
محققان با وام گرفتن ایده ها از یک تکنیک یادگیری ماشین به نام یادگیری متضاد و استفاده از آنها در خوشه بندی تصویر ، یک شکاف را پر کردند. این منجر به یک الگوریتم جدید شد که می تواند تصاویر نامشخص را 8 درصد بهتر از رویکرد پیشرفته دیگری طبقه بندی کند.
آنها همچنین از I-CON استفاده کردند تا نشان دهند که چگونه یک تکنیک debiasing داده برای یادگیری متضاد ایجاد می شود تا بتواند صحت الگوریتم های خوشه بندی را تقویت کند.
علاوه بر این ، جدول تناوبی انعطاف پذیر به محققان این امکان را می دهد تا ردیف ها و ستون های جدیدی را اضافه کنند تا انواع اضافی اتصالات DataPoint را نشان دهند.
در نهایت ، داشتن I-Con به عنوان یک راهنما می تواند به دانشمندان یادگیری ماشین کمک کند تا در خارج از جعبه فکر کنند ، آنها را ترغیب به ترکیب ایده ها به روشهایی که لزوماً به آنها فکر نمی کردند.
وی می افزاید: “ما نشان داده ایم که فقط یک معادله بسیار ظریف ، ریشه در علم اطلاعات ، به شما الگوریتم های غنی می دهد که 100 سال تحقیق در یادگیری ماشین را در بر می گیرد. این راه های جدید برای کشف را باز می کند.”
“شاید چالش برانگیزترین جنبه بودن یک محقق یادگیری ماشین در این روزها تعداد به ظاهر نامحدودی از مقالات باشد که هر سال ظاهر می شود. در این زمینه ، مقالاتی که الگوریتم های موجود را متحد و متصل می کنند از اهمیت زیادی برخوردار هستند ، اما از نظر علوم بسیار نادر هستند. I-Con نمونه ای عالی از چنین رویکرد یکپارچه ای ارائه می دهد و امیدوارم دیگران را به استفاده از رویکرد مشابهی از Damains of Enuressions بپردازند. مهندسی در دانشگاه عبری اورشلیم ، که در این تحقیق شرکت نکرد.
این تحقیق تا حدودی توسط شتاب دهنده اطلاعات مصنوعی نیروی هوایی ، موسسه ملی علوم AI برای هوش مصنوعی و تعامل اساسی و رایانه های Quanta تأمین شد.
منبع: https://news.mit.edu/1404/machine-learning-periodic-table-could-fuel-ai-discovery-0423
برای نگارش بخشهایی از این متن ممکن است از ترجمه ماشینی یا هوش مصنوعی GPT استفاده شده باشد
لطفا در صورت وجود مشکل در متن یا مفهوم نبودن توضیحات، از طریق دکمه گزارش نوشتار یا درج نظر روی این مطلب ما را از جزییات مشکل مشاهده شده مطلع کنید تا به آن رسیدگی کنیم
لطفا در صورت وجود مشکل در متن یا مفهوم نبودن توضیحات، از طریق دکمه گزارش نوشتار یا درج نظر روی این مطلب ما را از جزییات مشکل مشاهده شده مطلع کنید تا به آن رسیدگی کنیم
زمان انتشار: 1404-04-23 13:14:04
