از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



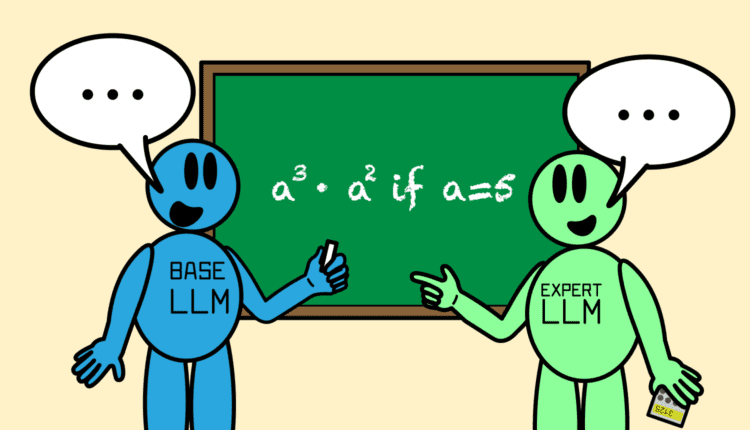
زمان لازم برای مطالعه: 5 دقیقه
تا به حال سوالی از شما پرسیده شده که فقط بخشی از پاسخ آن را می دانید؟ برای دادن پاسخ آگاهانه تر، بهترین حرکت شما این است که با یک دوست با دانش بیشتر تماس بگیرید روی موضوع
این مشارکتی process همچنین می تواند به مدل های زبان بزرگ (LLM) کمک کند تا دقت خود را بهبود بخشند. با این حال، آموزش به LLM ها برای تشخیص اینکه چه زمانی باید با مدل دیگری همکاری کنند، دشوار است روی یک پاسخ محققان آزمایشگاه علوم کامپیوتر و هوش مصنوعی MIT (CSAIL) به جای استفاده از فرمولهای پیچیده یا مقادیر زیادی از دادههای برچسبگذاری شده برای مشخص کردن جایی که مدلها باید با هم کار کنند، رویکردی ارگانیکتر را در نظر گرفتهاند.
الگوریتم جدید آنها که “Co-LLM” نام دارد، می تواند یک LLM پایه همه منظوره را با یک مدل تخصصی تر جفت کند و به آنها کمک کند تا با هم کار کنند. همانطور که اولی پاسخ می دهد، Co-LLM هر کلمه (یا نشانه) را در پاسخ خود بررسی می کند تا ببیند کجا می تواند پاسخ دقیق تری را از مدل متخصص بخواهد. این process منجر به پاسخ های دقیق تر به مواردی مانند درخواست های پزشکی و مسائل ریاضی و استدلال می شود. از آنجایی که مدل خبره در هر تکرار مورد نیاز نیست، این نیز منجر به تولید پاسخ کارآمدتر می شود.
برای تصمیمگیری زمانی که یک مدل پایه به کمک یک مدل متخصص نیاز دارد، چارچوب از یادگیری ماشین برای آموزش یک «متغیر سوئیچ» یا ابزاری استفاده میکند که میتواند شایستگی هر کلمه را در پاسخهای دو LLM نشان دهد. سوئیچ مانند یک مدیر پروژه است که مناطقی را پیدا می کند که باید با یک متخصص تماس بگیرد. برای مثال، اگر از Co-LLM بخواهید چند نمونه از گونههای خرس منقرض شده را نام ببرد، دو مدل با هم پاسخها را پیشنویس میکنند. LLM همهمنظوره شروع به جمعآوری پاسخ میکند، با متغیر سوئیچ در قسمتهایی که میتواند به نشانه بهتری نسبت به مدل خبره، مانند اضافه کردن سال انقراض گونه خرس، مداخله کند.
شانون شن، دانشجوی دکترای MIT در مهندسی برق و علوم کامپیوتر و وابسته به CSAIL که نویسنده اصلی است، میگوید: «با Co-LLM، ما اساساً یک LLM همهمنظوره را آموزش میدهیم تا در صورت نیاز، یک مدل متخصص را «تلفن» کنیم. روی مقاله جدید در مورد رویکرد ما از دادههای دامنه خاص برای آموزش مدل پایه در مورد تخصص همتای خود در زمینههایی مانند وظایف زیستپزشکی و سوالات ریاضی و استدلال استفاده میکنیم. این process به طور خودکار بخشهایی از دادهها را پیدا میکند که تولید مدل پایه سخت است و سپس به مدل پایه دستور میدهد به LLM خبره که از قبل آموزش داده شده است سوئیچ کند. روی داده های یک زمینه مشابه مدل همه منظوره، نسل «داربست» را فراهم می کند، و زمانی که فراخوانی می کند روی LLM تخصصی، متخصص را وادار می کند تا توکن های مورد نظر را تولید کند. یافتههای ما نشان میدهد که LLMها الگوهای همکاری را بهطور ارگانیک یاد میگیرند، شبیه اینکه چگونه انسانها تشخیص میدهند چه زمانی باید از یک متخصص برای پر کردن جاهای خالی استفاده کنند.
ترکیبی از انعطاف پذیری و واقعیت
تصور کنید از یک LLM همه منظوره بخواهید مواد تشکیل دهنده یک داروی تجویزی خاص را نام ببرد. ممکن است پاسخ نادرست بدهد، که نیاز به تخصص یک مدل تخصصی دارد.
برای نشان دادن انعطاف پذیری Co-LLM، محققان از داده هایی مانند مجموعه پزشکی BioASQ استفاده کردند تا یک LLM پایه را با LLM های خبره در حوزه های مختلف، مانند مدل مدیترون، که از قبل آموزش دیده است، ترکیب کنند. روی داده های پزشکی بدون برچسب این الگوریتم را قادر میسازد تا به سؤالاتی که معمولاً متخصص زیستپزشکی دریافت میکند، پاسخ دهد، مانند نامگذاری مکانیسمهای ایجادکننده یک بیماری خاص.
برای مثال، اگر از یک LLM ساده به تنهایی بخواهید که ترکیبات یک داروی تجویزی خاص را نام ببرد، ممکن است پاسخ نادرست بدهد. با اضافه شدن تخصص مدلی که در داده های زیست پزشکی تخصص دارد، پاسخ دقیق تری دریافت خواهید کرد. Co-LLM همچنین به کاربران هشدار می دهد که کجا پاسخ ها را دوباره بررسی کنند.
مثال دیگری از افزایش عملکرد Co-LLM: هنگامی که وظیفه حل یک مسئله ریاضی مانند “a3 · a2 اگر a=5” بود، مدل همه منظوره به اشتباه پاسخ را 125 محاسبه کرد. همانطور که Co-LLM مدل را برای همکاری بیشتر آموزش داد. با یک LLM ریاضی بزرگ به نام Llemma، آنها با هم تشخیص دادند که راه حل صحیح 3125 است.
Co-LLM پاسخ های دقیق تری نسبت به LLM های ساده تنظیم شده و مدل های تخصصی تنظیم نشده که به طور مستقل کار می کنند ارائه می دهد. Co-LLM می تواند دو مدل را که به طور متفاوت آموزش دیده اند برای کار با هم راهنمایی کند، در حالی که سایر روش های همکاری موثر LLM، مانند “Proxy Tuning” نیاز دارند که همه مدل های اجزای آنها به طور مشابه آموزش داده شوند. علاوه بر این، این خط پایه مستلزم آن است که هر مدل به طور همزمان برای تولید پاسخ مورد استفاده قرار گیرد، در حالی که الگوریتم MIT به سادگی مدل متخصص خود را برای توکن های خاص فعال می کند و منجر به تولید کارآمدتر می شود.
چه زمانی از متخصص بپرسید
الگوریتم محققان MIT نشان می دهد که تقلید از کار تیمی انسانی بیشتر می تواند دقت را در همکاری چند LLM افزایش دهد. برای بالا بردن بیشتر دقت واقعی خود، تیم ممکن است از اصلاح خود انسان استفاده کند: آنها در حال بررسی یک رویکرد تعویق قویتر هستند که میتواند زمانی که مدل متخصص پاسخ صحیحی ارائه نمیدهد، عقبنشینی کند. این ارتقاء به Co-LLM اجازه میدهد تا دوره را تصحیح کند تا الگوریتم همچنان بتواند پاسخ رضایتبخشی بدهد.
تیم همچنین مایل است مدل متخصص را (فقط از طریق آموزش مدل پایه) هنگامی که اطلاعات جدید در دسترس است، به روز کند و پاسخ ها را تا حد امکان به روز نگه دارد. این به Co-LLM اجازه می دهد تا به روزترین اطلاعات را با قدرت استدلال قوی جفت کند. در نهایت، این مدل می تواند با استفاده از آخرین اطلاعاتی که برای به روز رسانی آنها در اختیار دارد، به اسناد سازمانی کمک کند. Co-LLM همچنین می تواند مدل های کوچک و خصوصی را برای کار با یک LLM قدرتمندتر برای بهبود اسنادی که باید در سرور باقی بمانند، آموزش دهد.
کالین رافل، دانشیار دانشگاه تورنتو و مدیر تحقیقاتی در موسسه Vector، که درگیر نبود، میگوید: «Co-LLM یک رویکرد جالب برای یادگیری انتخاب بین دو مدل برای بهبود کارایی و عملکرد ارائه میکند. تحقیق کنید. از آنجایی که تصمیمات مسیریابی در سطح توکن گرفته می شود، Co-LLM یک روش ریز برای به تعویق انداختن مراحل تولید دشوار به یک مدل قدرتمندتر ارائه می دهد. ترکیب منحصر به فرد مسیریابی در سطح مدل-توکن نیز انعطاف پذیری زیادی را فراهم می کند که روش های مشابه فاقد آن هستند. Co-LLM به خط مهمی از کار کمک می کند که هدف آن توسعه اکوسیستم های مدل های تخصصی برای پیشی گرفتن از سیستم های گران قیمت هوش مصنوعی یکپارچه است.
شن این مقاله را با چهار زیرمجموعه دیگر CSAIL نوشت: دانشجوی دکترا هانتر لانگ ’17، MEng ’18; بایلین وانگ، پسادکتر سابق و محقق هوش مصنوعی اپل. یون کیم، استادیار مهندسی برق و علوم کامپیوتر MIT، و استاد و عضو کلینیک جمیل، دیوید سونتاگ دکترای 10، که هر دو بخشی از آزمایشگاه هوش مصنوعی MIT-IBM Watson هستند. تحقیقات آنها تا حدی توسط بنیاد ملی علوم، کمک هزینه تحصیلی فارغ التحصیلان علوم و مهندسی دفاع ملی (NDSEG)، آزمایشگاه هوش مصنوعی MIT-IBM Watson و آمازون پشتیبانی شد. کار آنها در نشست سالانه انجمن زبانشناسی محاسباتی ارائه شد.
منبع: https://news.mit.edu/1403/enhancing-llm-collaboration-smarter-more-efficient-solutions-0916
برای نگارش بخشهایی از این متن ممکن است از ترجمه ماشینی یا هوش مصنوعی GPT استفاده شده باشد
لطفا در صورت وجود مشکل در متن یا مفهوم نبودن توضیحات، از طریق دکمه گزارش نوشتار یا درج نظر روی این مطلب ما را از جزییات مشکل مشاهده شده مطلع کنید تا به آن رسیدگی کنیم
لطفا در صورت وجود مشکل در متن یا مفهوم نبودن توضیحات، از طریق دکمه گزارش نوشتار یا درج نظر روی این مطلب ما را از جزییات مشکل مشاهده شده مطلع کنید تا به آن رسیدگی کنیم
زمان انتشار: 1403-09-18 03:49:14
