از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



زمان لازم برای مطالعه: 3 دقیقه
خوشه بندی K-means یک الگوریتم یادگیری بدون نظارت است که داده ها را بر اساس گروه بندی می کند روی هر نقطه فاصله اقلیدسی تا یک نقطه مرکزی نامیده می شود نقطه مرکزی. مرکزها به وسیله تمام نقاطی که در یک خوشه هستند تعریف می شوند. الگوریتم ابتدا نقاط تصادفی را به عنوان مرکز انتخاب می کند و سپس تنظیم آنها را تا همگرایی کامل تکرار می کند.
نکته مهمی که هنگام استفاده از K-means باید به خاطر بسپارید این است که تعداد خوشه ها یک فراپارامتر است که قبل از اجرای مدل تعریف می شود.
K-means را می توان با استفاده از Scikit-Learn تنها با 3 خط کد پیاده سازی کرد. Scikit-Learn همچنین در حال حاضر یک روش بهینه سازی centroid در دسترس دارد، kmeans++، که به همگرایی سریعتر مدل کمک می کند.
برای اعمال الگوریتم خوشه بندی K-means، اجازه دهید بارگذاری شود پنگوئن های پالمر مجموعه دادهها، ستونهایی را انتخاب کنید که خوشهبندی میشوند و از Seaborn برای رسم نمودار پراکندگی با خوشههای کد رنگی استفاده کنید.
توجه داشته باشید: می توانید مجموعه داده را از اینجا دانلود کنید ارتباط دادن.
اجازه دهید import کتابخانه ها و بارگذاری مجموعه داده پنگوئن ها، برش آن به ستون های انتخاب شده و رها کردن ردیف هایی با داده های از دست رفته (فقط 2 مورد وجود دارد):
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
df = pd.read_csv('penguins.csv')
print(df.shape)
df = df(('bill_length_mm', 'flipper_length_mm'))
df = df.dropna(axis=0)
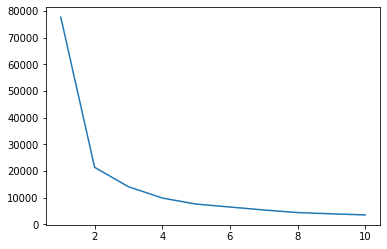
ما می توانیم از روش Elbow برای داشتن نشانه ای از خوشه ها برای داده های خود استفاده کنیم. این شامل تفسیر یک طرح خطی با شکل آرنج است. تعداد خوشه ها جایی است که آرنج خم می شود. محور x نمودار تعداد خوشه ها و محور y مجموع مربعات درون خوشه ها (WCSS) برای هر تعداد خوشه است:
wcss = ()
for i in range(1, 11):
clustering = KMeans(n_clusters=i, init='k-means++', random_state=42)
clustering.fit(df)
wcss.append(clustering.inertia_)
ks = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
sns.lineplot(x = ks, y = wcss);

روش elbow نشان می دهد که داده های ما دارای 2 خوشه است. بیایید داده ها را قبل و بعد از خوشه بندی رسم کنیم:
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15,5))
sns.scatterplot(ax=axes(0), data=df, x='bill_length_mm', y='flipper_length_mm').set_title('Without clustering')
sns.scatterplot(ax=axes(1), data=df, x='bill_length_mm', y='flipper_length_mm', hue=clustering.labels_).set_title('Using the elbow method');

این مثال نشان می دهد که چگونه روش Elbow زمانی که برای انتخاب تعداد خوشه ها استفاده می شود تنها یک مرجع است. ما قبلاً می دانیم که ما 3 نوع پنگوئن در مجموعه داده داریم، اما اگر بخواهیم تعداد آنها را با استفاده از روش Elbow تعیین کنیم، 2 خوشه نتیجه ما خواهد بود.
از آنجایی که K-means به واریانس داده ها حساس است، بیایید به آمار توصیفی ستون هایی که در حال خوشه بندی هستیم نگاه کنیم:
df.describe().T
این نتیجه در:
count mean std min 25% 50% 75% max
bill_length_mm 342.0 43.921930 5.459584 32.1 39.225 44.45 48.5 59.6
flipper_length_mm 342.0 200.915205 14.061714 172.0 190.000 197.00 213.0 231.0
توجه داشته باشید که میانگین از انحراف استاندارد (std) دور است، این نشان دهنده واریانس بالا است. بیایید سعی کنیم آن را با مقیاس دادن به داده ها با استاندارد Scaler کاهش دهیم:
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
scaled = ss.fit_transform(df)
حالا بیایید روش Elbow را تکرار کنیم process برای داده های مقیاس بندی شده:
wcss_sc = ()
for i in range(1, 11):
clustering_sc = KMeans(n_clusters=i, init='k-means++', random_state=42)
clustering_sc.fit(scaled)
wcss_sc.append(clustering_sc.inertia_)
ks = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
sns.lineplot(x = ks, y = wcss_sc);

این بار، تعداد خوشههای پیشنهادی 3 است. میتوانیم دادهها را با برچسبهای خوشه به همراه دو نمودار قبلی برای مقایسه رسم کنیم:
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(15,5))
sns.scatterplot(ax=axes(0), data=df, x='bill_length_mm', y='flipper_length_mm').set_title('Without clustering')
sns.scatterplot(ax=axes(1), data=df, x='bill_length_mm', y='flipper_length_mm', hue=clustering.labels_).set_title('With the Elbow method')
sns.scatterplot(ax=axes(2), data=df, x='bill_length_mm', y='flipper_length_mm', hue=clustering_sc.labels_).set_title('With the Elbow method and scaled data');

هنگام استفاده از K-means Clustering، باید تعداد خوشه ها را از قبل تعیین کنید. همانطور که در هنگام استفاده از روشی برای انتخاب خود دیدیم ک تعداد خوشهها، نتیجه فقط یک پیشنهاد است و میتواند تحت تأثیر میزان واریانس دادهها باشد. انجام یک تحلیل عمیق و تولید بیش از یک مدل با _k_های مختلف هنگام خوشه بندی بسیار مهم است.
اگر هیچ نشانه قبلی از تعداد خوشهها در دادهها وجود ندارد، آن را تجسم کنید، آزمایش کنید و تفسیر کنید تا ببینید آیا نتایج خوشهبندی منطقی است یا خیر. اگر نه، دوباره خوشه بندی کنید. همچنین، به بیش از یک متریک نگاه کنید و مدلهای مختلف خوشهبندی را نمونهسازی کنید – برای K-means، به امتیاز silhouette و شاید خوشهبندی سلسله مراتبی نگاه کنید تا ببینید آیا نتایج یکسان میمانند یا خیر.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-04 18:57:11
