از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
این فرمت سند قابل حمل (PDF) یک نیست WYSIWYG (آنچه می بینید همان چیزی است که به دست می آورید) قالب این برای پلتفرم-آگنوستیک، مستقل از سیستم عامل اصلی و موتورهای رندر توسعه داده شد.
برای دستیابی به این هدف، PDF ساخته شد تا از طریق چیزی بیشتر شبیه به یک زبان برنامه نویسی و متکی با آن تعامل داشته باشد. روی مجموعه ای از دستورالعمل ها و عملیات برای رسیدن به نتیجه. در واقع PDF است مستقر روی یک زبان برنامه نویسی – پست اسکریپتکه اولین دستگاه مستقل بود زبان توضیحات صفحه.
در این راهنما، ما استفاده خواهیم کرد بورب – یک کتابخانه پایتون که به خواندن، دستکاری و تولید اسناد PDF اختصاص یافته است. هم یک مدل سطح پایین (که به شما امکان میدهد به مختصات و طرحبندی دقیق در صورت استفاده از آنها دسترسی داشته باشید) و هم یک مدل سطح بالا (که در آن میتوانید محاسبات دقیق حاشیهها، موقعیتها و غیره را به یک مدیر طرحبندی واگذار کنید) ارائه میدهد. .
در این راهنما، روش درخواست را بررسی خواهیم کرد تشخیص کاراکتر نوری (OCR) روی یک سند پی دی اف اسکن شده
نصب borb
بورب را می توان از منبع دانلود کرد روی GitHub، یا نصب شده از طریق pip:
$ pip install borb
“سند PDF من متن ندارد!”
این یکی از کلاسیک ترین سوالات است روی هر انجمن برنامه نویسی یا میز کمک:
“به نظر می رسد سند من متنی در آن ندارد. کمک کنید؟”
یا:
“نمونه کد استخراج متن شما برای سند من کار نمی کند. چطور؟”
پاسخ اغلب به همان اندازه ساده است “اسکنر شما از شما متنفر است”.
اکثر اسنادی که این کار برای آنها کار نمی کند اسناد PDF هستند که اساساً تصاویر جلالی هستند. آنها حاوی تمام متا داده های مورد نیاز برای ایجاد یک PDF هستند، اما صفحات آنها فقط تصاویر بزرگ (اغلب با کیفیت پایین) هستند که با اسکن کاغذهای فیزیکی ایجاد می شوند.
در نتیجه، وجود دارد بدون رندر متن دستورالعمل های موجود در این اسناد و اکثر کتابخانه های PDF قادر به مدیریت آنها نخواهند بود. borbبا این حال، دوست دارد کمک کند و می تواند در این موارد با پشتیبانی داخلی از OCR استفاده شود.
در این بخش از یک ویژه استفاده خواهیم کرد EventListener اجرا نامیده می شود OCRAsOptionalContentGroup. این کلاس استفاده می کند tesseract (و یا به جای pytesseract) برای انجام OCR (تشخیص کاراکتر نوری) روی را Document.
اگر میخواهید درباره OCR در پایتون اطلاعات بیشتری کسب کنید، راهنمای ما برای تشخیص ساده نویسههای نوری با PyTesseract را بخوانید!
پس از اتمام، متن شناسایی شده مجدداً در هر صفحه به عنوان یک “لایه” ویژه درج می شود (در PDF به آن “گروه محتوای اختیاری” می گویند).
با بازیابی محتوا، ترفندهای معمول (SimpleTextExtraction) نتایج مورد انتظار را به همراه دارد.
شما با ایجاد روشی شروع خواهید کرد که یک تصویر PIL با مقداری متن در آن ایجاد می کند. این تصویر سپس در یک PDF درج می شود.
ایجاد یک تصویر
import typing
from pathlib import Path
from PIL import Image as PILImage
from PIL import ImageDraw, ImageFont
def create_image() -> PILImage:
img = PILImage.new("RGB", (256, 256), color=(255, 255, 255))
font = ImageFont.truetype("/usr/share/fonts/truetype/ubuntu/UbuntuMono-B.ttf", 24)
draw = ImageDraw.Draw(img)
draw.text((10, 10),
"Hello World!",
fill=(0, 0, 0),
font=font)
return img
حالا بیایید یک PDF با این تصویر بسازیم تا سند اسکن شده خود را نشان دهد، که قابل تجزیه نیست، زیرا حاوی متادیتا نیست:
import typing
from borb.pdf.canvas.layout.image.image import Image
from borb.pdf.canvas.layout.page_layout.multi_column_layout import SingleColumnLayout
from borb.pdf.canvas.layout.page_layout.page_layout import PageLayout
from borb.pdf.canvas.layout.text.paragraph import Paragraph
from borb.pdf.document import Document
from borb.pdf.page.page import Page
from borb.pdf.pdf import PDF
def create_document():
d: Document = Document()
p: Page = Page()
d.append_page(p)
l: PageLayout = SingleColumnLayout(p)
l.add(Paragraph("Lorem Ipsum"))
l.add(Image(create_image()))
with open("output_001.pdf", "wb") as pdf_file_handle:
PDF.dumps(pdf_file_handle, d)
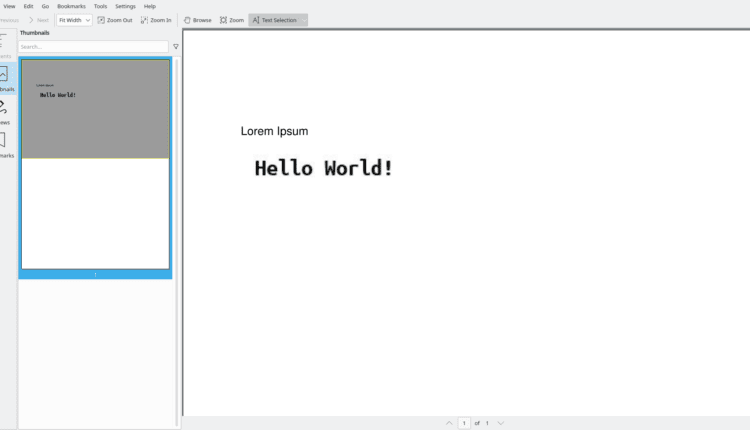
سند حاصل باید به شکل زیر باشد:

وقتی متن این سند را انتخاب می کنید، بلافاصله خواهید دید که در واقع فقط خط بالایی متن است. بقیه یک است تصویر با متن (تصویری که ایجاد کردید):

اکنون، اجازه دهید OCR را برای این سند اعمال کنیم و همپوشانی کنیم متن واقعی به طوری که قابل تجزیه می شود:
from pathlib import Path
from borb.toolkit.ocr.ocr_as_optional_content_group import OCRAsOptionalContentGroup
from borb.toolkit.text.simple_text_extraction import SimpleTextExtraction
def apply_ocr_to_document():
tesseract_data_dir: Path = Path("/home/joris/Downloads/tessdata-master/")
assert tesseract_data_dir.exists()
l: OCRAsOptionalContentGroup = OCRAsOptionalContentGroup(tesseract_data_dir)
doc: typing.Optional(Document) = None
with open("output_001.pdf", "rb") as pdf_file_handle:
doc = PDF.loads(pdf_file_handle, (l))
assert doc is not None
with open("output_002.pdf", "wb") as pdf_file_handle:
PDF.dumps(pdf_file_handle, doc)
می توانید ببینید که این یک لایه اضافی در PDF ایجاد کرده است. این لایه نامگذاری شده است “OCR توسط Borb”و حاوی دستورالعمل های رندر است borb دوباره درج شد Document.
می توانید نمایان بودن این لایه را تغییر دهید (این می تواند هنگام اشکال زدایی مفید باشد):


می توانید ببینید که borb برای اطمینان از دستور rendering postscript دوباره درج کرده است “سلام دنیا!” در سند موجود است. بیایید دوباره این لایه را مخفی کنیم.
به خاطر داشته باشید که OCR یک اکتشافی است. مکان و متن تطبیق ممکن است همیشه 100٪ درست نباشد. این فقط راه است. به طور معمول، شما لایه را پنهان نگه می دارید (اما قابل انتخاب) بنابراین تصویر اصلی در جای خود قرار می گیرد و می توانید تقریبی از آن را انتخاب یا کپی کنید.
اکنون (حتی با پنهان بودن لایه)، می توانید متن را انتخاب کنید:

و در صورت درخواست SimpleTextExtraction اکنون، شما باید بتوانید تمام متن موجود در آن را بازیابی کنید Document.
from borb.toolkit.text.simple_text_extraction import SimpleTextExtraction
def read_modified_document():
doc: typing.Optional(Document) = None
l: SimpleTextExtraction = SimpleTextExtraction()
with open("output_002.pdf", "rb") as pdf_file_handle:
doc = PDF.loads(pdf_file_handle, (l))
print(l.get_text_for_page(0))
def main():
create_document()
apply_ocr_to_document()
read_modified_document()
if __name__ == "__main__":
main()
این چاپ می کند:
Lorem Ipsum
Hello World!
عالی!
نتیجه
در این راهنما یاد گرفتهاید که چگونه OCR را در اسناد PDF اعمال کنید و اطمینان حاصل کنید که اسناد اسکن شده شما قابل جستجو و آماده برای پردازش آینده هستند.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-08 07:22:05
