از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
توطئه یک کتابخانه تجسم داده های پایتون مبتنی بر جاوا اسکریپت است که متمرکز است روی در ارتباط بودن و مبتنی بر وب تجسم ها این سادگی Seaborn، با API سطح بالا، و همچنین تعامل Bokeh را دارد.
علاوه بر عملکرد کتابخانه اصلی، با استفاده از داخلی Plotly Express با خط تیره، آن را به یک انتخاب شگفت انگیز برای برنامه های کاربردی مبتنی بر وب و داشبوردهای تعاملی مبتنی بر داده، که معمولاً به زبان نوشته می شوند، تبدیل می کند. فلاسک.
در این راهنما، نگاهی به روش ترسیم یک نوار پلات با Plotly.
نمودارهای میله ای بیشتر برای تجسم داده های طبقه بندی استفاده می شود، جایی که ارتفاع هر نوار تعداد رخدادهای آن دسته را نشان می دهد.
با پلاتلی یک پلات نواری را طراحی کنید
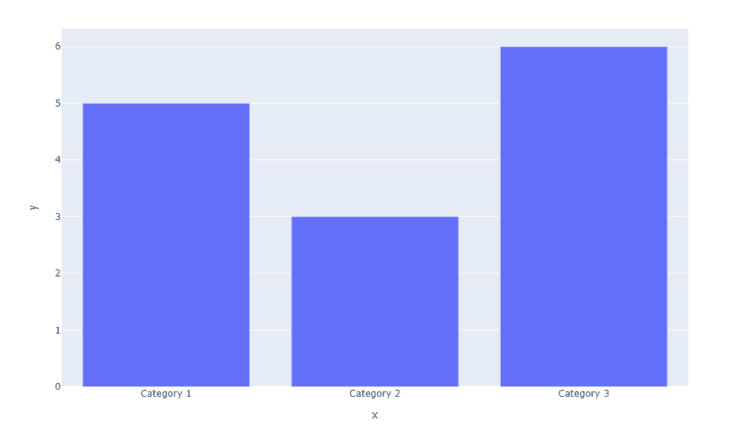
برای ترسیم یک Bar Plot در Plotly، به سادگی با آن تماس بگیرید bar() عملکرد Plotly Express (px) به عنوان مثال، ارائه x و y آرگومان هایی با داده های معتبر:
import plotly.express as px
x = ('Category 1', 'Category 2', 'Category 3')
y = (5, 3, 6)
fig = px.bar(x, y)
fig.show()
در اینجا، ما سه دسته داریم، به عنوان یک لیست که ما ارائه کرده ایم x آرگومان و چند مقدار اسکالر که برای آن ارائه کرده ایم y بحث و جدل. این منجر به یک طرح نوار ساده و بصری می شود:

با این حال، ما به ندرت در هنگام انجام تجسم داده ها با لیست ها کار می کنیم. اجازه دهید import را مجموعه داده های کاربران مخابرات و تجسم کنید InternetService و tenure ویژگی ها از طریق طرح نوار.
توجه داشته باشید: مجموعه داده ای که در ابتدا برای این مقاله استفاده می شد حذف شده است که با پیوند بالا جایگزین شده است. در حالی که به نظر می رسد همان مجموعه داده باشد، توجه داشته باشید که خروجی شما ممکن است متفاوت از آنچه در اینجا نشان داده شده است به نظر برسد.
را InternetService ویژگی یک ویژگی طبقه بندی است که مشخص می کند مشتری از کدام نوع خدمات استفاده می کند، در حالی که tenure یک ویژگی عددی است که نشاندهنده مدت زمانی است که یک مشتری در شرکت بوده است، در ماهها:
import pandas as pd
import plotly.express as px
df = pd.read_csv('telecom_users.csv')
print(df.head())
این نتیجه در:
gender SeniorCitizen tenure InternetService ...
0 Male 0 72 No ...
1 Female 0 44 Fiber optic ...
2 Female 1 38 Fiber optic ...
3 Male 0 4 DSL ...
4 Male 0 2 DSL ...
حال ، بیایید پیش برویم و این داده ها را به عنوان یک طرح نوار ترسیم کنیم:
import pandas as pd
import plotly.express as px
df = pd.read_csv('telecom_users.csv')
fig = px.bar(df, x = 'InternetService', y = 'tenure')
fig.show()
برای رسم داده ها از یک مجموعه داده، منبع داده را ارائه کرده ایم (df) به عنوان اولین آرگومان ، و نام ستون که می خواهیم به آن تجسم کنیم x و y استدلال ها نقشه ها این موارد را نقشه می کند ، داده ها را واکشی می کند و یک طرح تولید می کند:

اکنون ، طرح تولید شده توسط طرح ریزی در واقع هر نمونه را به یک انباشته کوچک جدا می کند بار از خودش روی این نمودار، از آنجایی که چندین ردیف یکسان هستند x ارزش ، برخلاف نقشه برداری ساده 1 به 1 مانند مثال اول.
ما می توانیم ببینیم انباشته تعداد ماههایی که آنها به طور موازی به مشتریان خود خدمت کرده اند. در حالی که 90 هزار ماه ممکن است به نظر برسد مجنون تعداد ماه ها (7500 سال)، میانه tenure است 29 ماه ها:
print(df('tenure').median())
تغییر رنگ طرح نوار با Plotly
تغییر رنگ هر یک از موارد فوق الذکر آسان است ، بر اساس روی هر متغیر دیگری که در مجموعه داده وجود دارد. اینها اغلب از دیگر ویژگی های طبقه بندی شده ، مانند gender یا SeniorCitizen.
گروهبندی نمونهها بر اساس ویژگی دیگری، a را ایجاد میکند طرح نوار گروهی، که بیشتر ترسیم می شوند بعد به دیگران. به سادگی با رنگ آمیزی نمونه ها بر اساس روی یکی دیگر از ویژگی های، ما یک طرح نوار گروهی انباشته، از آنجا که ما دو یا چند گروه از موارد یک خواهیم داشت روی بالای دیگری
بیایید یک بار دیگر به طرح نوار نگاهی بیندازیم ، یک بار بسته به هر نقشه رنگ آمیزی می کنیم روی را gender ویژگی:
import pandas as pd
import plotly.express as px
df = pd.read_csv('telecom_users.csv')
fig = px.bar(df, x = 'InternetService', y = 'tenure', color='gender')
fig.show()
اکنون ، طرح رنگی به طور پیش فرض اعمال می شود ، و نمونه ها بر اساس رنگ طبقه بندی می شوند ، بنابراین در طول طرح به هم نمی ریزند:

از آنجایی که ما چندین ردیف داریم که یکسان را به اشتراک می گذارند x مقادیر – اینها اساساً به عنوان میله های گروهی انباشته ترسیم شده اند.
اگر بخواهیم یک ویژگی متفاوت را ترسیم کنیم ، این پشته نمی شود (انتخاب باینری از ویژگی دیگری نیست) ، این طرح نسبتاً متفاوت به نظر می رسد:
import pandas as pd
import plotly.express as px
df = pd.read_csv('telecom_users.csv')
fig = px.bar(df, x='tenure', y='MonthlyCharges', color='tenure')
fig.show()

هنگام ارائه مقادیر رنگی زیادی مانند 0..70 از طریق tenure ویژگی – شیب های زیبایی را که در توطئه های خود شکل گرفته است ، خواهید دید.
Plot Grouped Bar Plot with Plotly
بعضی اوقات ، اگر به جای انباشت آنها ، میله ها را در کنار دیگری ترسیم کنیم ، تمایز ساده تر است روی روی هم این به ویژه زمانی مفید است که ویژگی های باینری داریم، مانند SeniorCitizen که فقط دو مقدار دارد شما واقعا می توانید داشته باشید n مقادیر موجود در ویژگی های شما در گروه ، بیشتر گروه ها اگر خیلی بزرگ باشند ، واقعاً از ما سود نمی برند.
برای انجام این کار، می توانیم به سادگی طرح بندی را به روز کنیم Figureو تنظیم کنید barmode به 'group':
import pandas as pd
import plotly.express as px
df = pd.read_csv('telecom_users.csv')
fig = px.bar(df, x = 'InternetService', y = 'tenure', color='gender')
fig.update_layout(barmode='group')
fig.show()
اکنون، مقایسه تعداد نمونه ها بسیار ساده تر است:

یک پلات نوار افقی با پلاتلی ترسیم کنید
برای ترسیم یک نوار میله به صورت افقی با استفاده از Plotly، می توانیم مقدار را تنظیم کنیم orientation استدلال به h (بر خلاف حالت پیش فرض v) هنگام ترسیم نمودار نوار:
import pandas as pd
import plotly.express as px
df = pd.read_csv('telecom_users.csv')
fig = px.bar(df, x='MonthlyCharges', y='tenure', color='tenure', orientation='h')
fig.show()
به خاطر داشته باشید که اگر می خواهید رابطه XY را همانطور که قبلا بود حفظ کنید، آن را تغییر می دهید x و y استدلال ها اجرای این کد نتیجه می دهد:

سفارش زمین های بار در پلاتلی
Plotly به طور خودکار میله ها را سفارش می دهد. شما می توانید مستقیماً این تنظیم را با به روز رسانی تغییر دهید Figure مولفه های.
می توانید سفارش دستی یا سفارش خودکار را انتخاب کنید. برای سفارش دستی، می توانید یک فرهنگ لغت حاوی نام ویژگی ها و ترتیب آنها را که منجر به یک ترتیب ثابت می شود، به category_orders بحث و جدل:
import pandas as pd
import plotly.express as px
df = pd.read_csv('telecom_users.csv')
fig = px.bar(df, x='InternetService', y='tenure', color='gender',
category_orders={"InternetService": ("DSL", "Fiber optic", "No"),
"gender": ("Female", "Male")})
fig.show()
اینجا، ما سفارش دادیم InternetService ویژگی به ترتیب خاصی که به صورت دستی تنظیم کردهایم و همچنین gender ویژگی.
ترسیم طرح نوار اکنون منجر به موارد زیر می شود:

روش دیگر، به خصوص اگر تعداد زیادی مقادیر ممکن وجود داشته باشد – ممکن است بخواهیم به Plotly اجازه دهیم به طور خودکار مقادیر ویژگی ها را مرتب و مرتب کند. ما می توانیم آنها را مرتب کنیم به طور قطعی یا به صورت عددی.
و هر دوی اینها را می توان در ادامه سفارش داد ascending یا descending سفارش. برای ترتیب عددی، ما را فراخوانی می کنیم total کلمه کلیدی، در حالی که ما فراخوانی می کنیم category کلمه کلیدی برای سفارش طبقه بندی.
بهطور پیشفرض، Plotly ترتیب را بر اساس تنظیم میکند روی داده های ارائه شده – در مورد ما، آن را به عنوان دستور داد total ascending. بیایید آن را تغییر دهیم total descending:
fig.update_layout(xaxis={'categoryorder':'total descending'})
این نتیجه در:

هنگام مرتب کردن طبقه بندی، از نظر واژگانی مرتب می شود:
fig.update_layout(xaxis={'categoryorder':'category ascending'})
این نتیجه در:

نتیجه
در این آموزش، نگاهی گذرا به روش ترسیم و سفارشی سازی نوار پلات با Plotly انداخته ایم.
اگر به تجسم دادهها علاقه دارید و نمیدانید از کجا شروع کنید، حتماً ما را بررسی کنید بسته کتاب روی تجسم داده ها در پایتون:
تجسم داده ها در پایتون با Matplotlib و Pandas کتابی است که طراحی شده است تا مبتدیان مطلق را با دانش پایه پایتون به Pandas و Matplotlib ببرد و به آنها اجازه دهد پایه ای قوی برای کار پیشرفته با این کتابخانه ها بسازند – از طرح های ساده گرفته تا طرح های سه بعدی متحرک با دکمه های تعاملی.
این به عنوان یک راهنمای عمیق عمل می کند که همه چیزهایی را که باید در مورد پانداها و Matplotlib بدانید، از جمله روش ساخت انواع طرح هایی که در خود کتابخانه تعبیه نشده اند را به شما آموزش می دهد.
تجسم داده ها در پایتونکتابی برای توسعه دهندگان پایتون مبتدی تا متوسط، شما را از طریق دستکاری ساده داده ها با پانداها راهنمایی می کند، کتابخانه های ترسیم هسته ای مانند Matplotlib و Seaborn را پوشش می دهد و به شما نشان می دهد که چگونه از کتابخانه های اعلامی و تجربی مانند Altair استفاده کنید. به طور خاص، در طول ۱۱ فصل، این کتاب ۹ کتابخانه پایتون را پوشش میدهد: Pandas، Matplotlib، Seaborn، Bokeh، Altair، Plotly، GGPlot، GeoPandas و VisPy.
این به عنوان یک راهنمای عملی و منحصر به فرد برای تجسم داده ها، در مجموعه ای از ابزارهایی که ممکن است در حرفه خود استفاده کنید، عمل می کند.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-11 04:49:05
