از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
تشخیص اشیا میدان بزرگی در بینایی کامپیوتری است و یکی از مهمترین کاربردهای بینایی کامپیوتر در طبیعت است. از یک طرف، میتوان از آن برای ساخت سیستمهای مستقلی استفاده کرد که عوامل را در محیطها هدایت میکنند – چه روباتهایی که وظایف را انجام میدهند یا ماشینهای خودران، اما این نیاز به تقاطع با زمینههای دیگر دارد. با این حال، تشخیص ناهنجاری (مانند محصولات معیوب روی یک خط)، مکان یابی اشیاء درون تصاویر، تشخیص چهره و کاربردهای مختلف دیگر تشخیص اشیا را می توان بدون تلاقی فیلدهای دیگر انجام داد.
تشخیص اشیا به اندازه طبقهبندی تصویر استاندارد نیست، عمدتاً به این دلیل که بیشتر پیشرفتهای جدید بهجای کتابخانهها و چارچوبهای بزرگ، معمولاً توسط محققان، نگهداریکنندگان و توسعهدهندگان منفرد انجام میشود. بستهبندی اسکریپتهای کاربردی ضروری در چارچوبی مانند TensorFlow یا PyTorch و حفظ دستورالعملهای API که تاکنون توسعه را هدایت کردهاند، دشوار است.
این امر تشخیص اشیاء را تا حدودی پیچیدهتر، معمولاً پرمخاطبتر (اما نه همیشه) و کمتر از طبقهبندی تصویر میسازد. یکی از مهمترین مزایای حضور در یک اکوسیستم این است که راهی برای جستجو نکردن اطلاعات مفید در اختیار شما قرار می دهد. روی شیوه ها، ابزارها و رویکردهای خوب برای استفاده. با تشخیص شی – بیشتر آنها باید تحقیقات بیشتری انجام دهند روی چشم انداز میدان را به خوبی در دست بگیرید.
تشخیص اشیا با PyTorch/TorchVision’s RetinaNet
torchvision پروژه چشم انداز رایانه ای PyTorch است و با ارائه اسکریپت های تبدیل و تقویت، یک باغ وحش مدل با وزن ها، مجموعه داده ها و ابزارهای از پیش آموزش دیده که می تواند برای یک پزشک مفید باشد، توسعه مدل های CV مبتنی بر PyTorch را آسان تر می کند.
در حالی که هنوز در نسخه بتا و بسیار آزمایشی است – torchvision یک API نسبتاً ساده Object Detection را با چند مدل برای انتخاب ارائه می دهد:
- R-CNN سریعتر
- رتینا نت
- FCOS (RetinaNet کاملا کانولوشنال)
- SSD (VGG16 backbone… ykes)
- SSDLite (ستون اصلی MobileNetV3)
در حالی که API به اندازه برخی دیگر از API های شخص ثالث صیقلی یا ساده نیست، نقطه شروع بسیار مناسبی برای کسانی است که هنوز امنیت بودن در اکوسیستمی را که با آن آشنا هستند ترجیح می دهند. قبل از رفتن به جلو، مطمئن شوید که PyTorch و Torchvision را نصب کرده اید:
$ pip install torch torchvision
اجازه دهید برخی از توابع ابزار، مانند read_image()، draw_bounding_boxes() و to_pil_image() برای سهولت در خواندن، نقاشی کنید روی و خروجی تصاویر و به دنبال آن وارد کردن RetinaNet و وزنه های از پیش آموزش داده شده آن (MS COCO):
from torchvision.io.image import read_image
from torchvision.utils import draw_bounding_boxes
from torchvision.transforms.functional import to_pil_image
from torchvision.models.detection import retinanet_resnet50_fpn_v2, RetinaNet_ResNet50_FPN_V2_Weights
import matplotlib.pyplot as plt
RetinaNet از یک ستون فقرات ResNet50 و یک شبکه هرمی ویژگی (FPN) استفاده می کند. روی بالای آن در حالی که نام کلاس پرمخاطب است، نشان دهنده معماری است. بیایید یک تصویر با استفاده از requests کتابخانه و ذخیره آن به عنوان یک فایل روی درایو محلی ما:
import requests
response = requests.get('https://i.ytimg.com/vi/q71MCWAEfL8/maxresdefault.jpg')
open("obj_det.jpeg", "wb").write(response.content)
img = read_image("obj_det.jpeg")
با یک تصویر در جای خود – می توانیم مدل و وزن های خود را نمونه سازی کنیم:
weights = RetinaNet_ResNet50_FPN_V2_Weights.DEFAULT
model = retinanet_resnet50_fpn_v2(weights=weights, score_thresh=0.35)
model.eval()
preprocess = weights.transforms()
این score_thresh آرگومان آستانه ای را تعریف می کند که در آن یک شی به عنوان یک شی از یک کلاس شناسایی می شود. به طور شهودی، آستانه اطمینان است، و اگر مدل کمتر از 35٪ مطمئن باشد که به یک کلاس تعلق دارد، ما یک شی را به یک کلاس طبقه بندی نمی کنیم.
بیایید تصویر را با استفاده از تبدیلهای وزنهایمان از قبل پردازش کنیم، یک دسته ایجاد کنیم و استنتاج را اجرا کنیم:
batch = (preprocess(img))
prediction = model(batch)(0)
همین است، ما prediction فرهنگ لغت دارای کلاسها و مکانهای شی استنتاج شده است! اکنون، نتایج در این فرم برای ما چندان مفید نیستند – میخواهیم برچسبها را با توجه به ابردادهها از وزنها استخراج کنیم و جعبههای مرزبندی را ترسیم کنیم، که میتوان از طریق این کار انجام داد. draw_bounding_boxes():
labels = (weights.meta("categories")(i) for i in prediction("labels"))
box = draw_bounding_boxes(img, boxes=prediction("boxes"),
labels=labels,
colors="cyan",
width=2,
font_size=30,
font='Arial')
im = to_pil_image(box.detach())
fig, ax = plt.subplots(figsize=(16, 12))
ax.imshow(im)
plt.show()
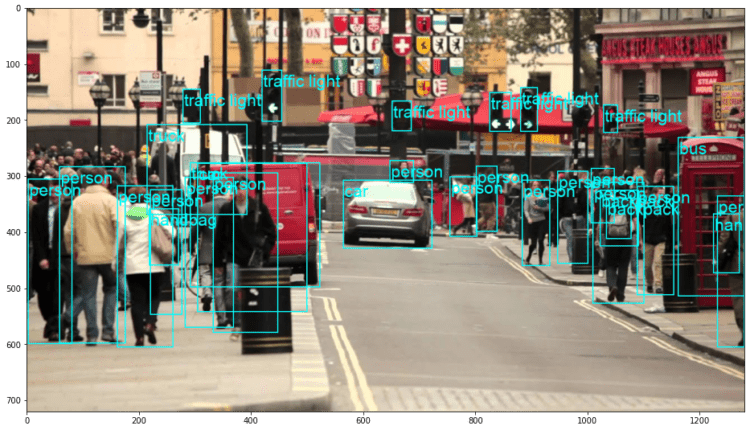
این نتیجه در:

رتینا نت در واقع فردی را که پشت ماشین نگاه می کند طبقه بندی کرد! این یک طبقه بندی بسیار دشوار است.
شما می توانید RetinaNet را به یک FCOS (RetinaNet کاملاً کانولوشنال) با جایگزینی تغییر دهید retinanet_resnet50_fpn_v2 با fcos_resnet50_fpn، و استفاده کنید FCOS_ResNet50_FPN_Weights وزن ها:
from torchvision.io.image import read_image
from torchvision.utils import draw_bounding_boxes
from torchvision.transforms.functional import to_pil_image
from torchvision.models.detection import fcos_resnet50_fpn, FCOS_ResNet50_FPN_Weights
import matplotlib.pyplot as plt
import requests
response = requests.get('https://i.ytimg.com/vi/q71MCWAEfL8/maxresdefault.jpg')
open("obj_det.jpeg", "wb").write(response.content)
img = read_image("obj_det.jpeg")
weights = FCOS_ResNet50_FPN_Weights.DEFAULT
model = fcos_resnet50_fpn(weights=weights, score_thresh=0.35)
model.eval()
preprocess = weights.transforms()
batch = (preprocess(img))
prediction = model(batch)(0)
labels = (weights.meta("categories")(i) for i in prediction("labels"))
box = draw_bounding_boxes(img, boxes=prediction("boxes"),
labels=labels,
colors="cyan",
width=2,
font_size=30,
font='Arial')
im = to_pil_image(box.detach())
fig, ax = plt.subplots(figsize=(16, 12))
ax.imshow(im)
plt.show()
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-04 04:25:05
